
|
|
|
Abstracts
| |
Resource Allocation and Utilization in the Blue Gene/L Supercomputer (Abstract)
Tamar Domany, IBM Haifa Labs
IBM has recently announced its new BlueGene family of supercomputers. BlueGene /L is a first member of this family. The design of BG/L is substantially different from traditional large clusters with SMP nodes. BlueGene/L has a scalable and extendable cellular architecture. It is composed of 64K compute nodes (cells), connected in a 3D torus topology. With 64K nodes, BlueGene/L aims at peak performance of 180-360 teraops per second. The BlueGene/L machine of 16K nodes is expected to be the fastest supercomputer in the world in the upcoming Top500 list.
One of the key factors for the high utilization of this machine is efficient and scalable job scheduling. Scalability is achieved by sacrificing granularity of management. Partitions (isolated subsets of nodes allocated to a job) are allocated on the basis of composite allocation units, thus dealing with an effectively much smaller system, while preserving the topology of the allocated partitions. Another challenge handled by BG/L job scheduling is the coexistence of mesh and toroidal partitions, specifically, toroidal partitions, which require additional communication links to close a torus. This may prevent the allocation of other isolated partitions that could otherwise use those links. Job scheduling for BG/L uses the novel multi-toroidal topology of Blue Gene/L for efficient coexistence of multiple isolated toroidal partitions without wasting too many network links-a significant advantage compared with the traditional 3D toroidal machines.
In this talk, we will describe the novel network architecture of BlueGene/L's 3D computational core, and a preliminary analysis of its properties and advantages compared with traditional systems. We will discuss the algorithmic framework for allocation of computational and communication resources, and present simulation results for resource utilization in BlueGene/L.
High Speed Total Order for SAN Infrastructure (Abstract)
Ilya Shnayderman, Danny Dolev, Tal Anker, Gregory Greenman, The Hebrew University of Jerusalem
The performance of many high performance distributed systems may be limited by performing "Total Order" of transaction messages. Specifically, some of the emerging Storage Area Networks (SANs) today use "Total Order" as a basis for management of meta-data servers. The required number of meta-data management transactions in a SAN may be very high, reaching the order of 40K ordered messages per second. This may adversely affect the current known performance of Total Order protocols.
The goal of the methodology presented in this paper is to achieve a hardware based coordinator, while using standard off-the-shelf hardware components. The proposed architecture uses two commodity Ethernet switches. The switches are edge devices, which support legacy layer 2 features, 802.1q VLANs and inter VLAN routing that are connected via a Gigabit Ethernet link and a cluster of dual homed PC's (two NICs per PC) that are connected to both switches. One of the switches functions as the coordinator for the cluster.
Since the commodity switch supports wirespeed on its Gigabit link, we can achieve near wirespeed traffic of a totally ordered stream of messages. Figure 1 shows the general network configuration of both the network (the switches) and the nodes attached to them. We experimented with configurations in which all nodes are both senders and receivers (all-to-all configurations), and with configurations in which the sets of senders and receivers were disjointed. We also experimented with different message sizes.
Table 1 presents throughput and latency measurements for the all-to-all configurations. The nodes generate traffic at the maximal rate bounded by the flow control mechanism. Two different latency values are presented: PO Latency and UTO Latency. We define the PO Latency to be the time that elapses between a transmission of message by the sender and its reception back at the sender (received from the network).
The UTO Latency is defined as the time elapsed between when a message is transmitted by the sender and the time the sender receives ACKs for this message from every receiver.
| Nodes Number |
Throughput Mb/s |
PO Latency ms |
UTO Latency ms |
| 3 |
361.745 |
2.183 |
4.163 |
| 4 |
375.369 |
3.398 |
5.362 |
| 5 |
383.927 |
3.410 |
6.782 |
Table 1: Throughput and Latency
We also performed an experiment with disjoint sets of receivers and senders. In this experiment we simulated a SAN environment where the load can be characterized by a very large amount of small messages. We used a similar approach as in the Nagle algorithm in order to cope with small messages. The senders aggregated small messages (64B) into large frames up to jumbo frame size (9000B). This allowed us to achieve throughput of 630 Mb/s, which accounts for more than one million messages per second!
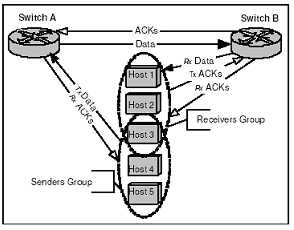
Figure: 1 Architecture
Scalability Issues in Storage Area Networks (Abstract)
Eitan Maggeni, StoreAge
Storage Area Networks (SAN) represent a potential for significant improvement in IT infrastructure. In particular, they offer the consolidation of storage capacity, storage performance and storage services. They also have the potential for being a key building block for the "on demand computing" paradigm.
However, in order to maximize benefits and justify the paradigm change and compensate for the difficulties in the transition period, SANs must be highly scalable. Today SANs are quite small in comparison with the total IT infrastructure of the organization. SANs that connect more than 100 servers are very rare. On the other hand, organizations that have more than 1000 servers are very common.
The key reason for the slow progress in SAN deployment is the limited scalability and hence the limited benefit. The key difficulties in designing highly scalable SANs are the need to resolve basic issues associated with SAN management, heterogeneity, security, and business continuity.
This presentation addresses these issues and some architectural solutions that enable the practical deployment of very large SANs.
Virtualization Using Linux & Open source (Abstract)
Ami Shlezinger, Israel Aircraft Industries Ltd
We aim to exploit the Linux and the open source world to build a scaled out virtualized architecture. The presentation will cover the advantages of the Linux and open source model and IAI Linux Virtual Server implementation.
Virtualization enabled IAI to move from server base architecture to service base architecture. The Linux Virtual Server feature enables logical name assignment to each service, and a set of computers to each logical name. This architecture provides simplified management, preventive maintenance during work time, improved application availability, and a simple scalability route.
Information vs. Speed Tradeoff in Journal (Abstract)
Philip Derbeko, SANRad
Journal (a.k.a. logging) is a unique and a very powerful virtualization feature. Although journaling has been used extensively in many computing areas , little information exists regarding the use of the journal mechanism at block-level storage devices. In this work, we consider an "in the data path" open storage system with as minimal assumptions on the device as possible. This setup enables us to discuss a wide range of the systems, without limiting ourselves to a high-end market part. It is worth noting that the proposed design enables one to build a fast and reliable journal for the discussed systems.
The first contribution of this presentation is an observation that some information can be traded for speed with no degradation in journal reliability. We view the amount of saved information as a "reliability requirement" of an application. For example, an application that does not permit the loss of any information has the highest reliability requirements. We show that different storage applications have variable reliability requirements, where the tightest requirements mean maximum I/O operations per write command. Therefore, forcing a common set of requirements on all journal applications may result in unnecessary I/O penalties in some cases. The discussed journal applications include log-based snapshot, continuous backup, and mirror consistency problems. We analyze the reliability requirements of each of the discussed applications and show the differences between them. We also show the possible performance gain from each piece of discarded information for every application.
The second part of this work is a description of a journal design. As mentioned above, journal applications differ in their requirements in terms of performance, reliability, interface, start-up time, storage demands, etc. In order for a single system to support all the mentioned applications, the journal implementation has to be as flexible as possible. This work shows a design that enables this flexibility and the customization of requirements for every application. The requirements can vary in reliability demands, the amount of stored journal meta-data, efficient defragmentation techniques, crash recovery, etc. This way, the proposed design enables a seamless coexistence of various journal applications on a single system.
Among the current uses of the journal are file systems [1], databases, operating systems, events, messages and many others (see [2]).
References
- Mendel Rosenblum and John K. Ousterhout. The design and implementation of a log-structured file system. ACM Transactions on Computer Systems, 10(1):26-52, 1992.
- Michel Ruffin. A survey of logging uses. Technical Report 36, Broadcast Esprit Project, February 1994. Also available as University of Glasgow (Scotland), Fide2 Report 94-82.
Distribution & Consistency Services (DCS) - Towards Flexible Levels of Availability (Abstract)
Eliezer Dekel, IBM Haifa Labs
Different applications require different levels of replication guarantees in order to provide better service (e.g., high availability, scalability). For some components, it is enough to replicate using unreliable multicast. These components will be able to continue service (e.g., on another machine) with some previous copy of the state (order, timing, or synchronization are not important). Other components might require replication with guaranteed delivery and total order. In order to continue service, these components will need to have the latest computed state. These two kinds of applications represent two points in the spectrum of replication requirements. Providing a customized replication service to each application requires a major investment.
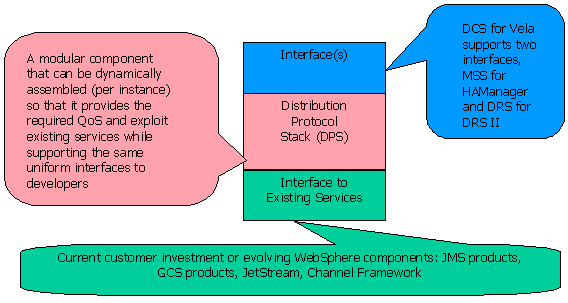
Figure 2: DCS and its interfaces
DCS supports WebSphere components' state replication requirements (e.g., HTTP session and stateful Beans) as well as the distribution and synchronization of WebSphere artifacts for performance, scalability, and availability. There are three parts to a DCS component (see Figure 2): application interface , distribution protocol stack (DPS), and system interface. The application interfaces provide abstractions that allow the exploitation of the row services provided by the DPS. WAS 6.0 release will support two application interfaces: Membership and Synchrony Service (MSS) and Data Replication Service (DRS). These interfaces are used by the HAManager Framework and the DRS correspondingly. The DPS is based on our Versatile Replication Infrastructure (VRI), and is configurable with respect to its delivery guarantees. DCS components should be able to exploit existing customer investment in terms of software and hardware as well as evolving WebSphere components. Existing investment can range from a JMS component as a transport layer, through cluster platform GCS capabilities, to special hardware like InfiniBand. Examples of WebSphere components are JetStream or the Channel Framework. Exploitation of such investments is supported by the flexible design of the DPS and the system interface.
There are two main versions of DCS: Core DCS and Data DCS (a.k.a. Slave DCS). There is one core DCS per process (JVM) and it provides membership services among peer processes (JVMs) in a WebSphere cell. These processes together form a core group. A cell may have one or more named core groups. Components within these processes can be members of application groups. Application groups are subsets of the core groups. A Data DCS component can be associated with each member of an application group. There can be several Data DCS instances per process. Data DCS instances rely on membership information provided by the core group.
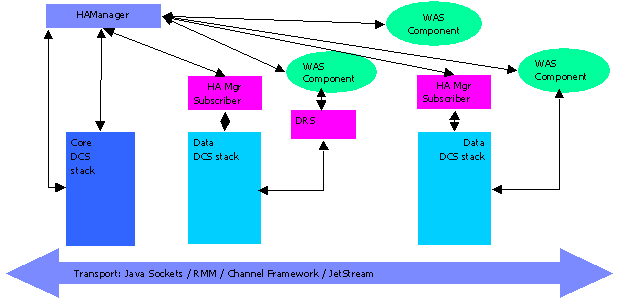
Figure 3 The Big Picture
AGRID - Distributed and Autonomous Agent-based Resource Management and Scheduling Middleware (Abstract)
Yoav Levy, Tsahi Birk Electrical Engineering Department, Technion
Current efforts in Grid computing mainly focus on the management of large collections of processing machines (e.g., desktop workstations) that are accessed and monitored by central schedulers. Such management middleware exploits the advantages of size and offer poor QoS, especially in WAN-based settings as the Internet.
A number of attempts, for example Condor-G, GRaDS, and Nimrod-G, have been made to develop computational economy based scheduling systems. However, these systems operate on a "top down'' basis and have a number of limitations, in that they assume knowledge of all the jobs on the grid, they require the ability to manage the scheduling of jobs on grid nodes, and they assume a direct linkage between the "grid to node'' and "within node'' scheduling processes.
I propose AGRID, a distributed and autonomous agent-based resource management and scheduling middleware, targeted at large computer clusters connected via the Internet as a Grid. AGRID utilizes market-based algorithms executed by intra-cluster competing agents to achieve temporal resource allocations while adjusting to changes in resource performance and job requirements.
In this talk, I will survey related work, present the architecture of AGRID and the operation of its core algorithms, discuss initial results acquired using a prototype of AGRID running exemplifying scenarios, and conclude with highlights of future work.
Keynote: Storage Aggregation for Performance and Availability: The Path from Physical RAID to Virtual Objects (Abstract)
Garth Gibson, Co-founder and Chief Technology Officer Panasas, Inc. Associate Professor CMU
Almost two decades ago I characterized five ways that multiple small disks could be used to "virtualize" a single large disk for better cost-performance and availability. Called the five levels of Redundant Arrays of Inexpensive Disks (RAID), this work started me on a career of storage systems research. Years later, with the advent of packetized SCSI over Fibrechannel networks, it became clear to me that disks would come out from behind servers and become first class citizens on a variety of networks, increasing parallelism, addressable storage, and the variety of fault domains. Beginning as Network Attached Secure Disks (NASD) and evolving into Object Storage Devices (OSD), such devices virtualize storage extents, encapsulating layout of variable length related data with extensible attributes and per-object access control enforced in each device. Now almost ten years of research has been done in multiple institutions, I have turned to commercializing the concepts in the Panasas Storage Cluster and others have completed the first round of standardization. In this talk I will review the principles of RAID and object storage and discuss how Panasas combines RAID and object storage into a new level of storage virtualization enabling advances in high performance and high availability.
Bio:
Garth Gibson is co-founder and Chief Technology Officer at Panasas Inc and an associate professor of Computer Science and Electrical and Computer Engineering at Carnegie Mellon University. Garth received a Ph.D. in Computer Science from the University of California at Berkeley in 1991. While at Berkeley he did the groundwork research and co-wrote the seminal paper on RAID, then Redundant Arrays of Inexpensive Disks, for which he received the 1999 IEEE Reynold B. Johnson Information Storage Award for outstanding contributions in the field of information storage. Joining the faculty at Carnegie Mellon University in 1991, Garth founded the CMU's Parallel Data Laboratory and the Network Attached Storage Device (NASD) working group of the National Storage Industry Consortium (NSIC). His NASD research with CMU and NSIC is a basis for the Storage Networking Industry Association's Object-based Storage Devices (OSD) technical working group, and its sister ANSI T10 OSD working group. Garth sits on a variety of academic and industrial service committees including the Technical Council of the Storage Networking Industry Association and the steering committee of the USENIX Conference on File and Storage Technologies (FAST).
Multilevel Cache Management Based on Application Hints (Abstract)
Gala Yadgar, Assaf Schuster, Dr. Michael Factor, Computer Science Department, Technion
While most caches are managed by the LRU replacement scheme, many schemes were proposed which differentiate between blocks based on the requesting application, or even the block's file [1]. They were designed to work in the file system cache, mostly because of the lack of information about the block's attributes anywhere outside the file system. A way to pass such information to the I/O system has been suggested in [2], and has been implemented in the Linux 2.4.2 kernel.
We propose an optimal offline algorithm for replacement in multiple levels of cache. It is an extension of Belady's MIN [3], which is optimal for one level of cache. In order to manage two levels of cache, we use the DEMOTE operation [4]. Blocks read from disk are saved only in the higher level. The lower level cache is used to save blocks evicted from the higher level ("demoted"), simulating one large cache.
This offline algorithm was used as a basis for the construction of an online algorithm, which relies on information passed to it by the application in order to approximate the offline decision.
Databases are examples of applications where the access pattern can be easily predicted, making useful hints available to the cache [1]. We chose as our application the PostgreSQL database, with the workload of queries from the TPCH benchmark. Hints were generated using the output of the DB's "explain" command.
Our algorithm receives as input a classification of blocks into ranges. The access pattern for the blocks in each range (loop, sequential, random), and the frequency of access to the range is also provided. The marginal gain of each range is calculated, and the cache space is divided among ranges.
We used the DB traces to simulate the offline optimal algorithm, the online approximation of it, and the best-known existing algorithms [4,5]. All were run on two levels of cache. The miss rate was calculated by dividing the number of disk accesses (second level misses) by the total number of block accesses. First, our simulation showed that there is still a significant gap in the hit rate between current management algorithms and the optimal management. This gap was as high as 400% in the extreme case, and was in the range of 2-11% in most cases. It also demonstrated that our approximation of the offline algorithm could imitate the optimal management, and further reduce this "distance" to optimal management.
References
- R.H. Patterson, G.A. Gibson, E. Ginting, D. Stodolsky, and J. Zelenka. Informed prefetching and caching. In Proceedings of the Fifteenth ACM Symposium on Operating Systems Principles, pages 79-95, December 1995.
- Tsipora Barzilai, Gala Golan. Accessing Application Identification Information in the Storage Tier. Disclosure IL8-2002-0055, IBM Haifa Labs, November 2002.
- L.A. Belady, A study of replacement algorithms for a virtual-storage computer. IBM Sys. J, vol. 5, no. 2, pp. 78-101, 1966.
- Theodore M. Wong and John Wilkes, My cache or yours? Making storage more exclusive, In Proc. of the USENIX Annual Technical Conference, 2002, pp 161-175.
- Nimrod Megiddo and Dharmendra S. Modha, ARC: A SELF-TUNING, LOW OVER-HEAD REPLACEMENT CACHE, USENIX File and Storage Technologies Conference (FAST), March 31, 2003, San Francisco, CA.
Storage System & Application in the Consumer Electronics World (Abstract)
Stephen Cumpson, Philips Research
Storage systems in the consumer electronics world were historically based on tape or optical recording and the storage was removable and application specific. Good examples are VHS, DV camcorders, CD's and DVD's. The convergence of the consumer electronics and information technology worlds are changing CE storage systems drastically. We are seeing the introduction of HDD based products in both the home and mobile products and, in parallel, a significant market driven focus on connectivity has emerged.
The combination of significant amounts of embedded storage with a vision of a connected planet brings about a number of new issues for CE systems. We are faced with an array of storage architectures from direct attached storage, block based plug and play devices such as USB and 1394 devices, through to fully networked devices using wired and wireless Ethernet technology. We are faced with a bewildering amount of stored content where a consumer may choose from 100's of hours of video, 1000's of songs and 10,000's of photographs.
Within Philips Research, we are studying quality of service issues related to the streaming of multiple standard and high-definition video streams for both direct attached and networked storage. Issues addressed are data access block sizes, file system and network latencies, file system fragmentation and power outage robustness for both the direct attached and networked variants. Our work in this area focuses on Linux for test implementations and has led to the Active Block I/O Scheduling System presented at the 2004 Ottawa Linux Symposium and the 2004 Linux Kongress.
Within both home and mobile media servers, we are studying embedded metadata databases to enable consumers to easily find and retrieve desired content from the large pool of available content. Within CE devices, there are significant resource constraints on processors and memory, while the desired functionality that a consumer expects shows no constraints. Consumers demand immediate user interface updates and the responsiveness they are accustomed to on a fully-fledged personal computer.
Parts of our work focus on optimizing CE based storage systems to satisfy our consumers. Furthermore, we are studying distributed metadata systems such that consumers may be oblivious to where content is actually stored since CE home networks will consist of heterogeneous devices. Our work in these areas has been presented at the 2004 CeBit and at PerWare 2005 in conjunction with the 3rd IEEE PerCom 2005 Conference.
In all of these areas, there is the challenge that the system must be simple to use, sensible in operation, and extremely low cost.
Challenges and Solutions in Remote Mirroring (Abstract)
Aviad Zlotnik, IBM Haifa Labs
In the era of worldwide terror threats, recovering from disasters has become a primary concern of big and small organizations. One of the basic requirements of disaster recovery is mirroring data in remote locations. Mirroring involves an inherent trade-off between response time and data loss, but is not allowed to impact data consistency or data integrity. Huge data repositories that span more than a single storage control unit create special consistency challenges.
This presentation will explain the inherent trade-off and the special challenges of remote mirroring, and describe IBM's solutions-Metro Mirroring and Global Mirroring.
Modeling Disk Activity Using Very Little Data (Abstract)
Eitan Bachmat, Ben Gurion University
In large, heterogeneous, and distributed storage systems, one needs to model the behavior of disks and other system components using very little information. Models which use very little information cannot be accurate. A big question, therefore, comes to mind: Can we find other properties of models which might make them useful despite being inaccurate?
We claim that giving upper or lower bound estimates can be useful in solving several optimization problems. We show that some simple and old models provide approximate upper bound estimates on disk drive contention using very little data.
The proofs use the theory of metric spaces and in particular are related to some results of Von Neumann and Schoenberg dating back to the 1930's.
We provide an application of these results to the problem of configuring a storage system.
|
|
|
|
|