
Reflections on 2022 and a look towards what’s next
Reflections on 2022 and a look towards what’s next
Research organizations are often asked about their impact. In the case of IBM Research, we have been pushing the boundaries of computing for almost 80 years, and it would be impossible to talk about the history — and future — of computing without the achievements of our community. It's an impact trajectory that is only accelerating.
By pioneering nanosheets, we have invented the high-volume manufacturing transistor architecture for the next decade. And because we are the trusted innovation partner of so many companies and governments, we are playing an indispensable role in revitalizing the semiconductor industry, from the US to Japan. We have built the world’s largest fleet of quantum computers, we are creating the first quantum-centric supercomputers, and pioneering a new industry. We are making the world quantum-safe, having developed with our collaborators three out of the four quantum-safe algorithms that NIST has selected for cryptographic standardization. We are also extending Red Hat’s industry-leading hybrid cloud platform to seamlessly deploy the most advanced and trustworthy AI for enterprises.
The purpose of this Annual Letter is to share with all of you the extraordinary body of work that is the foundation of what’s next in computing. You will see that it is a lot, but that is because we get a lot done. I hope you enjoy it!
I believe that this decade, we will see fundamental shifts in how the world computes. The ways that computer systems are architected, deployed, and used will be dramatically altered. Semiconductors, systems, AI, quantum computing, and hybrid cloud will continue to advance, but more importantly, they will converge in a computing platform characterized by its computational power, security, and simplicity of use, management, and operation. Quantum computing, classical computing, and fully multimodal AI will multiply their advantages when used collectively in this platform to solve some of the hardest challenges facing society, science, and business.
In this post, we will highlight the major trends we see emerging across these areas of research, and the work we carried out in 2022 that brings us closer to the vision outlined above. For a complete list of all the research we carried out this year, you can visit our publications page. You can navigate the sections of the post at your preference through the table of contents below:
Nanosheets and chiplets are the transistor and semiconductor technology of the next decade.
Over the past two years, we have lived through a semiconductor chip shortage that has highlighted the critical role of semiconductors not just in computers but in the commodity items we use every day. At the same time, the demand for compute power in data centers continues to grow, and AI applications are becoming ever more complex and computationally intense. Addressing these issues will require innovations in semiconductors. We believe that vertical chip integration will lead to the next generation of chips , and packaging breakthroughs for high-performance computing, including 3D chiplets, will provide hardware advances to improve AI computations. In-memory computing offers another opportunity to further improve energy efficiency for AI computations. We also believe that the trend of separating compute from storage that has allowed more flexible scaling and lower prices will continue.
In May 2021, we debuted our second-generation nanosheet CMOS technology, the 2 nm node, which will enable 50 billion to 100 billion transistors to be placed on a single chip. It could improve the performance of computing devices by 45%, or their energy efficiency by 75%, when compared to 7 nm technology. It was named one of the best inventions of 2022 by Time Magazine. To continue to advance to 1nm and beyond, we are investigating ruthenium for wiring and backside power distribution network technology. Ruthenium formed by a subtractive patterning method can also be potentially used for a new type of interconnect integration scheme.

Shifting from planar to three-dimensional device construction improves the control and uniformity of devices, and allows us to introduce new concepts to boost performance. Heterogeneous integration, along with chiplets, helps improve efficiency and reduce costs.
In 2022, we established an advanced C4 micro-bump line and developed laser-based debonding capabilities with Tokyo Electron. These are key building blocks for 3D chiplets. We are also developing materials for logic and chiplets.
The recent focus on optimizing chip design and architecture for specialized computing has improved the energy efficiency of computations. In 2019, IBM launched the AI Hardware Center to develop a full-stack solution to improve the energy efficiency of AI. In 2022, we continued to leverage approximate computing to minimize computations and data transfer between memory and processor without sacrificing accuracy.
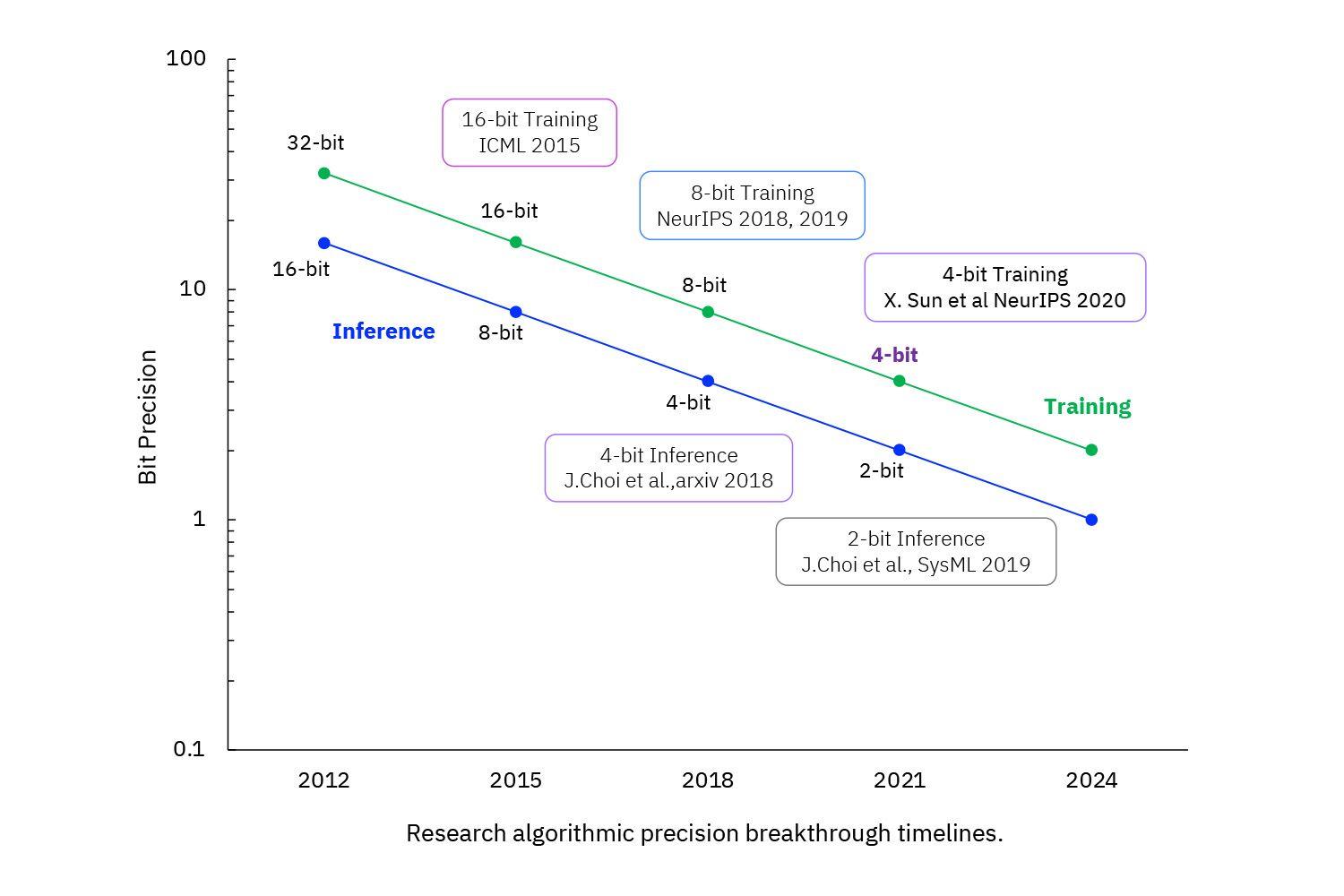
This work was showcased in the IBM AIU, a chip designed to run AI computations dramatically more efficiently than a CPU.

Beyond reduced precision, we have continued to push the field of analog or in-memory computing. We demonstrated key improvements for phase change memory (PCM) for inference at a system level and resistive RAM (RRAM) at a materials and device level.
Another example of a highly specialized computing system is IBM z16, a system specialized for transaction processing that allows Linux workloads to run with 75% less energy than x86. At IBM, we provided real time AI integrated in critical workloads for z16, capable of 3.5 million inferences per second, with 1 millisecond latency. This required inventing the deep learning compiler, machine learning acceleration (SNAP/ML), AI embedded in DB2/zOS, accelerated open-source AI libraries, optimized AI batch scheduling, and AI that identifies problems for IT operations. We developed 7 nm technology enhancements, as well as library development, chip verification tools, and high-speed I/O with associated PLL designs. Wazi as a Service, the IBM Digital Assets Platform, Hyper Protect services, and LinuxONE Bare Metal provide ease of use and access to z16. We also co-invented the COBOL automatic binary optimizer, and Service Designer, which helps to refactor monolithic applications.
To advance data storage, we enabled Flash Core Modules for IBM FlashSystem, which resulted in 50% higher effective capacity with the same physical capacity. We have also been increasing the density and speed of tape storage for hyperscalers. In particular, the new design of the Diamondback Tape Library is expected to provide a 2.5 times capacity increase.
We have also formed key partnerships to advance semiconductor research and development. In March, we served as a founding member of the American Semiconductor Innovation Coalition (ASIC), a group that has expanded to more than 160 companies, universities, startups, and nonprofits united to advocate for the National Semiconductor Technology Center (NSTC) and National Advanced Packaging Manufacturing Program. Central to this vision is a technical agenda focused on democratizing access to prototyping, and workforce development.

In October 2022, we were honored to welcome U.S. President Joe Biden to the IBM facility in Poughkeepsie, New York, home to the world’s largest fleet of quantum computers. In December, we announced a partnership with the newly formed Japanese semiconductor foundry Rapidus, whose investors include major firms such as Sony, Toyota, SoftBank, and NTT. The partnership will help Rapidus develop leading-edge 2 nm technology for manufacturing in the second half of this decade. In a separate partnership with Tokyo Electron, we successfully implemented a new process for bonding and debonding 300 mm wafers to silicon carriers. This process is critical for 3D chip stacking. We also revealed initial performance metrics for VTFET, the new vertical transistor architecture we are developing with Samsung, showing that it is possible to scale VTFET designs beyond the performance of 2 nm node nanosheets.
Going forward, investigating the fundamental material limits of copper, new interconnects, and other developments to enable scaling to 1 nm and beyond will be key semiconductor research activities for us in 2023 and beyond. We will also deliver capabilities for die-to-wafer hybrid bonding technology and 3D chiplet reliability learning.
To support the deployment of AI foundation models efficiently at scale, we are also developing innovations from scalable training tools and workflows to middleware, systems, and custom hardware accelerators. We will see all this in a full-stack architecture with virtualized and cloud operations for higher utilization, along with algorithms designed for distributed AI, and software optimized for end-user productivity. All together, we call this AI-centric supercomputing. This will lead us to more efficient scaling of accurate AI foundation models that can be taken into production faster.

Multi-cloud computing will enable seamless deployment of enterprise production-level AI at scale.
We are seeing several major trends defining inflection points in AI and hybrid cloud, and the two technologies converging. There are three trends poised to transform the current cloud computing landscape:
- Cloud infrastructure is becoming increasingly decentralized due to the low-latency computing requirements of AI workloads at the edge, sovereign cloud and data residency requirements, and the rising costs of operating on a global public cloud.
- Specialized, best-in-class capabilities across infrastructure, platform, and the full software stack are more widely available.
- More solutions based on open source are offered as services or platforms by cloud providers.
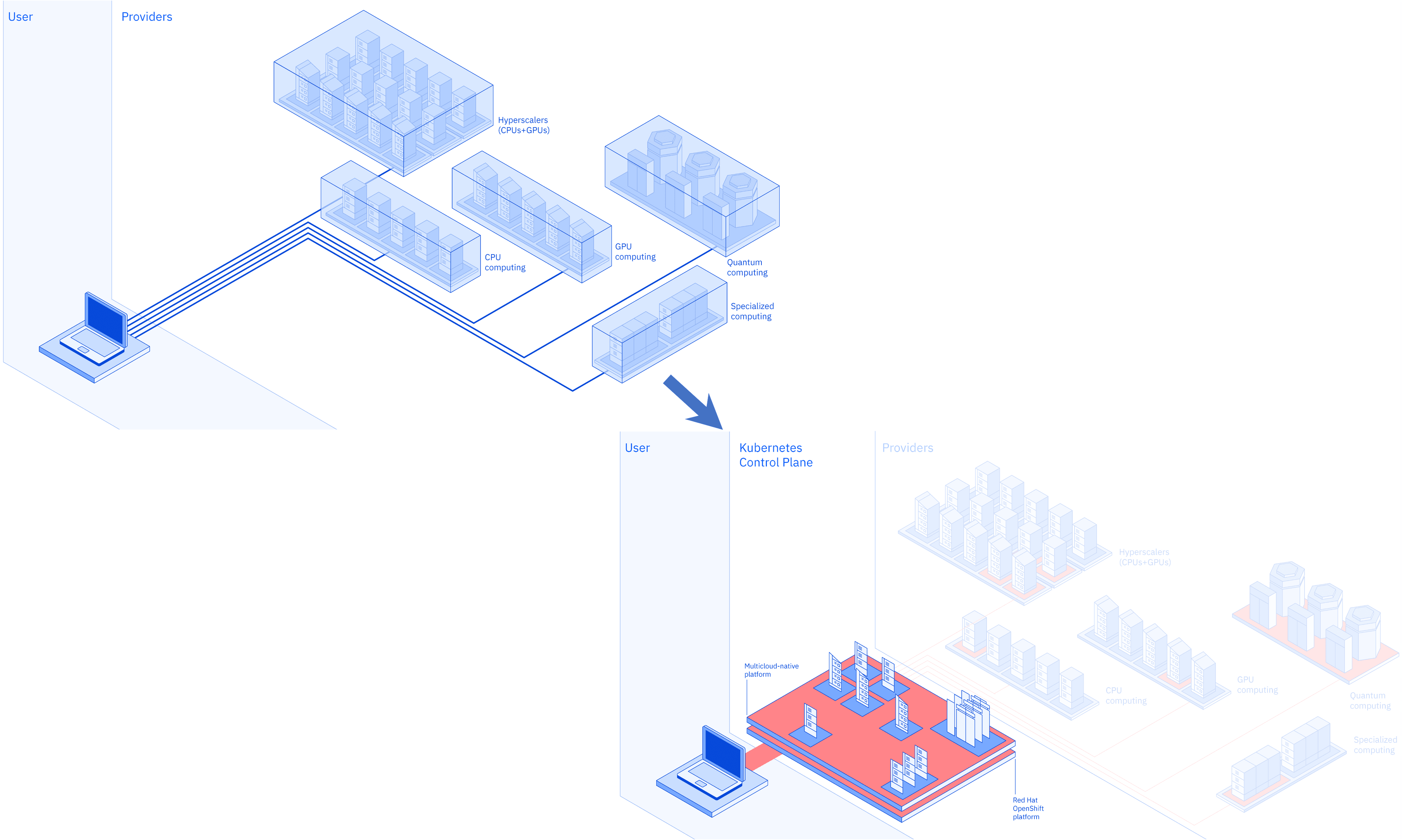
These trends point toward a shift from the traditional public cloud to a new interconnected and composable computing fabric. Applications could be built by seamlessly composing and integrating infrastructure, platform, tools, and services from multiple clouds—with simplicity, security, and sustainability. We are working to build such a truly multi-cloud native platform, and AI will help orchestrate and manage it. We aim to ensure consistency of the platform and core services across all deployment locations and address data locality, latency, and regulatory constraints.
In AI, meanwhile, we have seen a shift in the traditional approach to natural language understanding (NLU) with the emergence of large language models that work by mapping a sequence of words into high dimensional real-valued spaces to provide a contextualized representation of the word sequence that can be used for a variety of tasks. These tasks include NLU tasks like part-of-speech tagging, named entity recognition, parsing, text classification, or sentiment detection, natural text generation and machine translation. Foundation models are an example of these large-scale deep learning models that represent a once-in-a-decade paradigm shift for AI in enterprise. But for that, the entire lifecycle of foundation models, from pre-training to fine-tuning to inferencing, needs to be hardened and simplified for enterprise-level production. Hybrid cloud tools can help do just that.
To simplify the deployment of production-level foundation models at scale, we are developing a new full, cloud-native, customizable AI stack built on top of OpenShift. This stack will evolve to be integrated into the aforementioned future multi-cloud computing platform and deliver truly multi-cloud native AI, with frictionless, dynamic composability of AI applications and services.
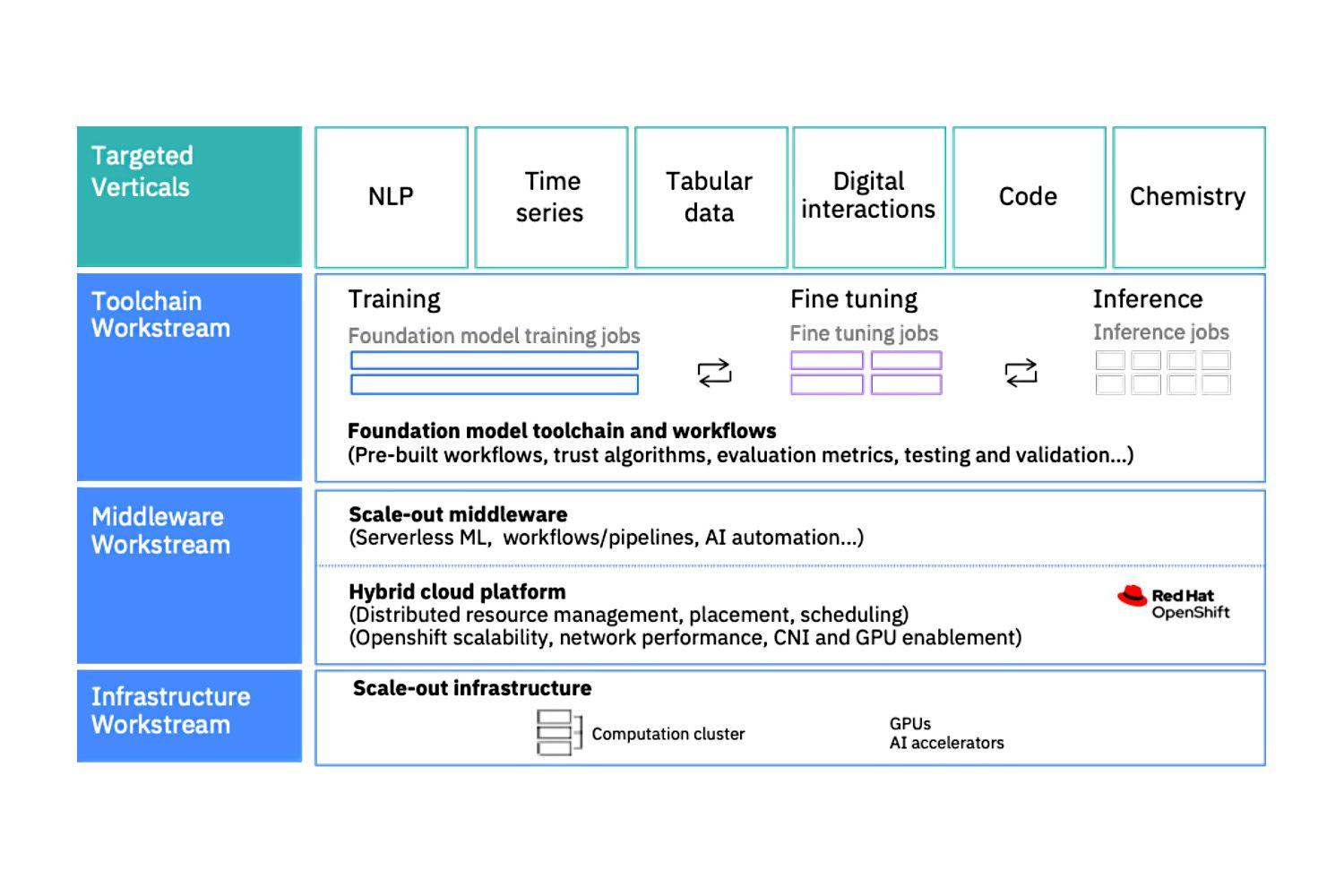
As part of the stack infrastructure, we brought online a new AI-optimized cloud-native supercomputer configured with OpenShift.
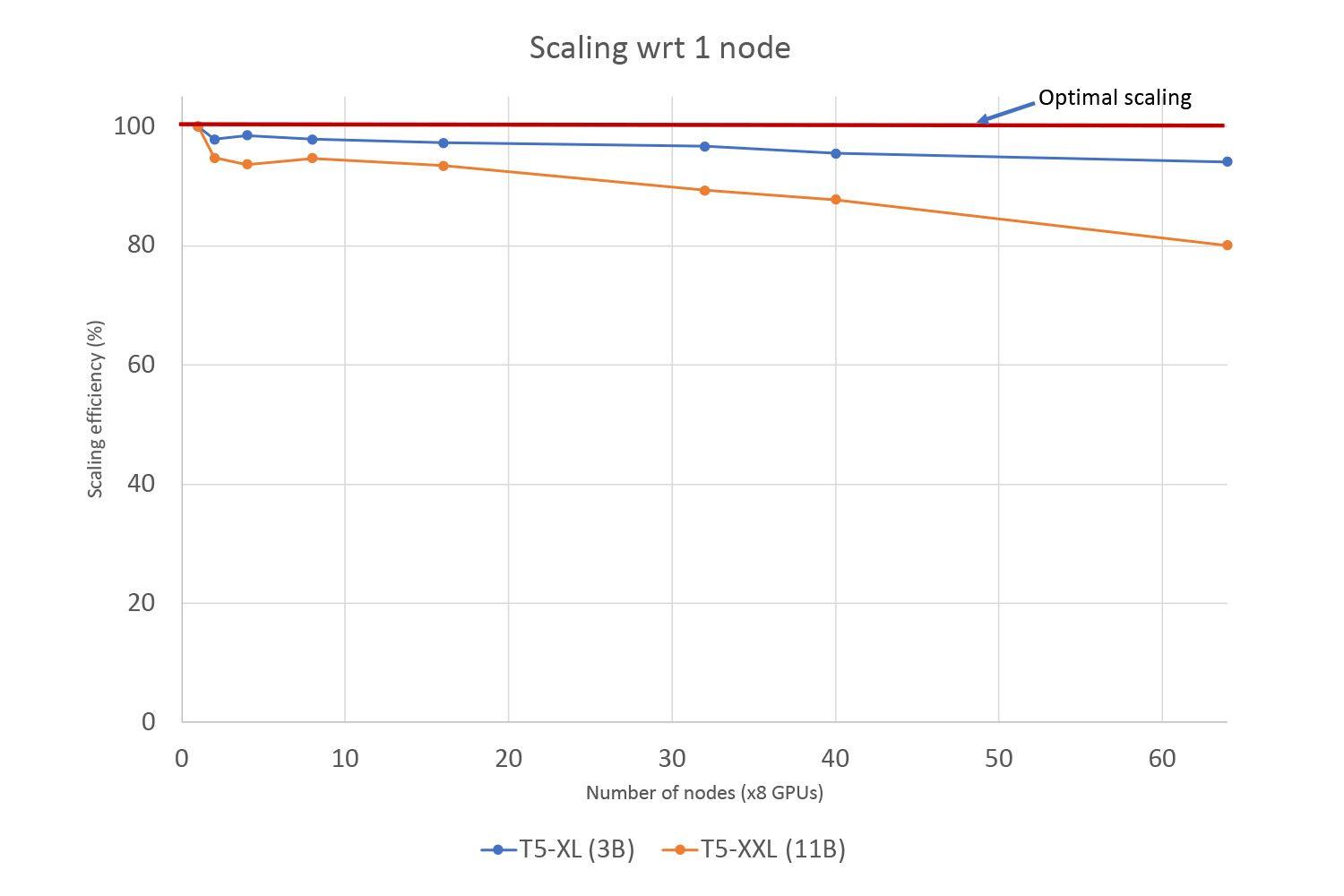
Working with PyTorch, we demonstrated a greater than 90% GPU utilization of the AI cloud supercomputer for distributed training jobs with up to 11 billion parameters over standard Ethernet based networks, approaching what was achievable in traditional supercomputing environments.
We have been working on a new data fabric and AI technologies to handle data discovery and integration, data governance, data annotation, as well as distributed AI model training, model optimization and deployment, and monitoring during inference. It automatically enforces governance policies, and policy-based data placement and caching to optimize the trade-offs between compute, network, and cost. These capabilities rely heavily on our work on enrichment of heterogeneous metadata to find the right data for the right task and have it available via the desired interfaces. We also incorporated intelligent observability and orchestration of distributed data and AI pipelines by pushing compute to data or by moving data to the compute while satisfying governance constraints. Our AI-based capabilities for data summarization and labeling have the potential to reduce the data traffic between 10 and 100 times within edge deployments and significantly reduce the time to build better models with more representative datasets. Out-of-distribution (OOD) detection can be used to detect abnormal data and monitor the performance of deployed models.
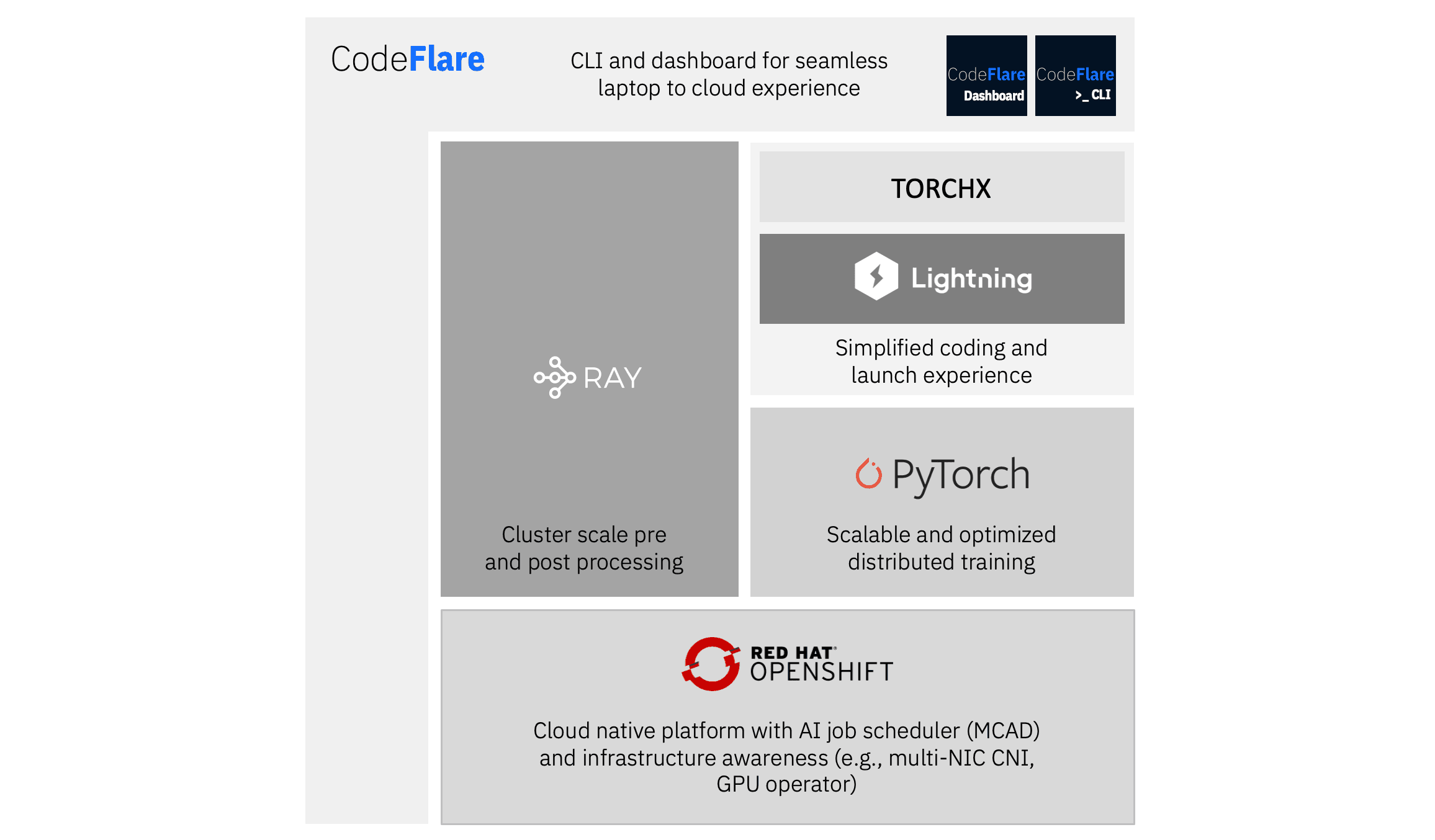
The foundation model stack includes a Kubernetes native scheduler to manage multiple jobs with job queuing, gang and topology-aware scheduling, load-aware scheduling, prioritization, and quota management. These enhancements lead to better elasticity, improved resource utilization, and faster iteration time. We will continue to work on the stack in 2023 to include automatic hyper-parameter optimization and model selection over a collection of machine-learning pipelines.
To further facilitate a simplified user experience, the stack also provides the CodeFlare command-line interface (CLI) and dashboard. It supports a single pane for observability of the full stack using a desktop CLI and dashboard, including information such as GPU utilization and application metrics like loss, gradient norm, and others. It also includes live and interactive dashboards, and automation to run use cases.
We are applying AI to refactor applications to transform them into cloud-based microservices. We are also automating microservice decomposition to move monolithic enterprise applications to cloud-native architectures. For example, we introduced a novel technique that improves the partition quality of state-of-the-art algorithms to decompose large scale applications into microservices. It substantially reduces distributed transactions, lowers the overall latency of the deployed microservice application by 11%, and increases throughput by 120% on average.
A key aspect of evolving today’s hybrid cloud to the new multi-cloud platform is the universal control plane. It is responsible for orchestrating the deployment of multi-cloud applications, including provisioning and configuring required runtimes and services, deploying the application logic on the runtimes and services, and setting up any specified security and compliance controls that have been specified. Trusted, enterprise-grade connectivity in the multi-cloud is crucial. We are contributing to Red Hat’s open-source project kcp to leverage it in creating a Kubernetes-based control plane for the multi-cloud.
We are building a new open multi-cloud network connectivity fabric to standardize the data plane and the control plane functionalities necessary for enabling secure cross-vendor interaction, as well as for negotiating and coordinating application-level data flows between different networking providers.
We have been developing various technologies to improve observability at various parts of the IT stack. At the platform level, we have focused on logging treating logs as an expensive resource, just like CPU, memory, and storage. We have been developing a framework called Log Flow Control to manage logging pipelines for better observability. It is an IBM Research contribution to Red Hat’s OCP 4.12. Full-stack multi-cloud observability will be key to domain-specific control planes for multi-cloud networking, data, and security management.
We must also make sure that the multi-cloud native platform meets our sustainability goals. We started with full-stack energy and carbon measurements that enable baseline quantification and optimization. AI can help find the best configuration that minimizes a cloud system’s carbon footprint.
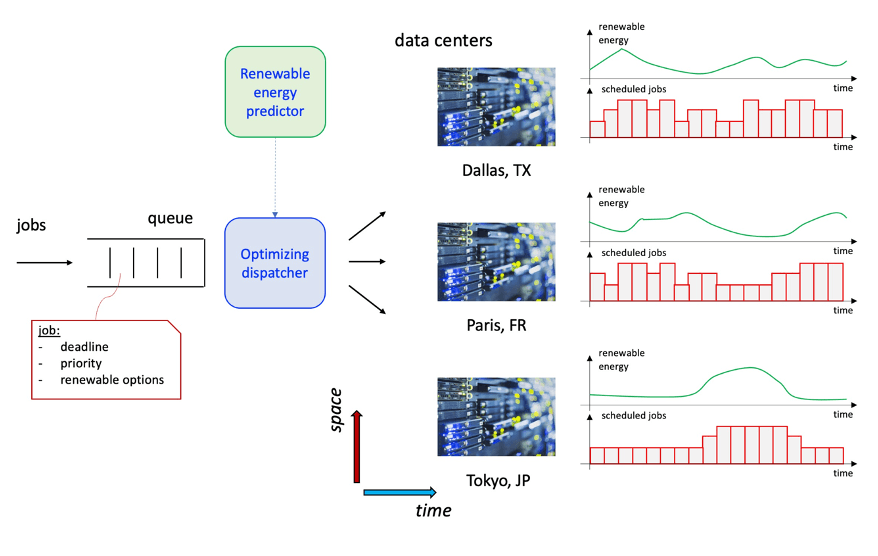
Our full stack-approach to improving sustainability combines innovations at every level of the computing stack — from energy-efficient processors and accelerators to serverless computing to optimize the placement and efficiency of workloads. One promising direction is to match renewable energy from the grid dynamically, shifting workloads across a multi-cloud environment to address energy shortages and fluctuations in renewable energy supply.
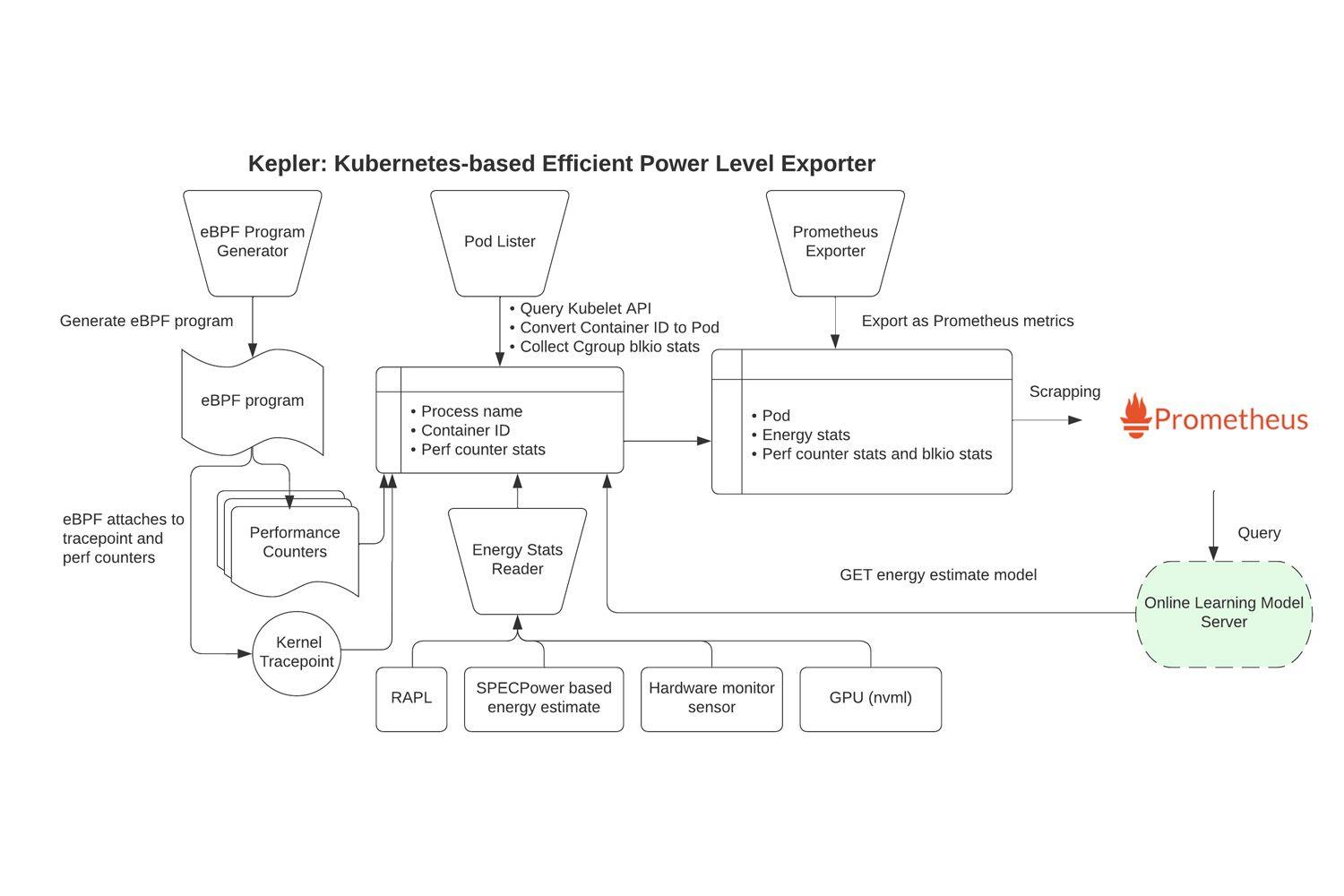
Another is to use performance counters to do a fine-grained analysis of each containerized application and optimize their energy consumption. That is what we implemented in Kepler, an open-source project we pioneered in 2022 with Red Hat.
In 2022, we used our foundation model stack to advance the state-of-the-art in many different modalities, such as tabular data and time series data (building on previous work that formed the basis of validation with enterprise data). A particularly exciting development was in molecular discovery, where we demonstrated novel antivirals discovered entirely by AI using a generative foundation model and experimentally validated in a wet lab. MolFormer, our large chemical language model, demonstrated state-of-the-art performance on several benchmarks. We also incorporated grammar learning in generative modeling to reduce by orders of magnitude the size of datasets needed for learning. This data-efficient generative model generates high-quality molecules and polymers from a sequence of production rules, with grammar optimization incorporating additional chemical knowledge into the model.
Another example is our work on AI for code. Project Wisdom for Red Hat, built on the foundation model stack, automates the generation of high quality Ansible code through a natural-language interface. You can use English sentences to write the commands, for example, “configure webapp setting” or “install nodejs dependencies” and Wisdom fills the code for the task and builds the requested automation workflow. It produces an Ansible playbook that you can accept as is or customize.
It works seamlessly with context and switches smoothly between different clouds.
Project Wisdom scored better than Copilot and Codex on performance while using significantly fewer model parameters, indicating how purpose-built AI foundation models can be higher quality, faster, more scalable, and more efficient.
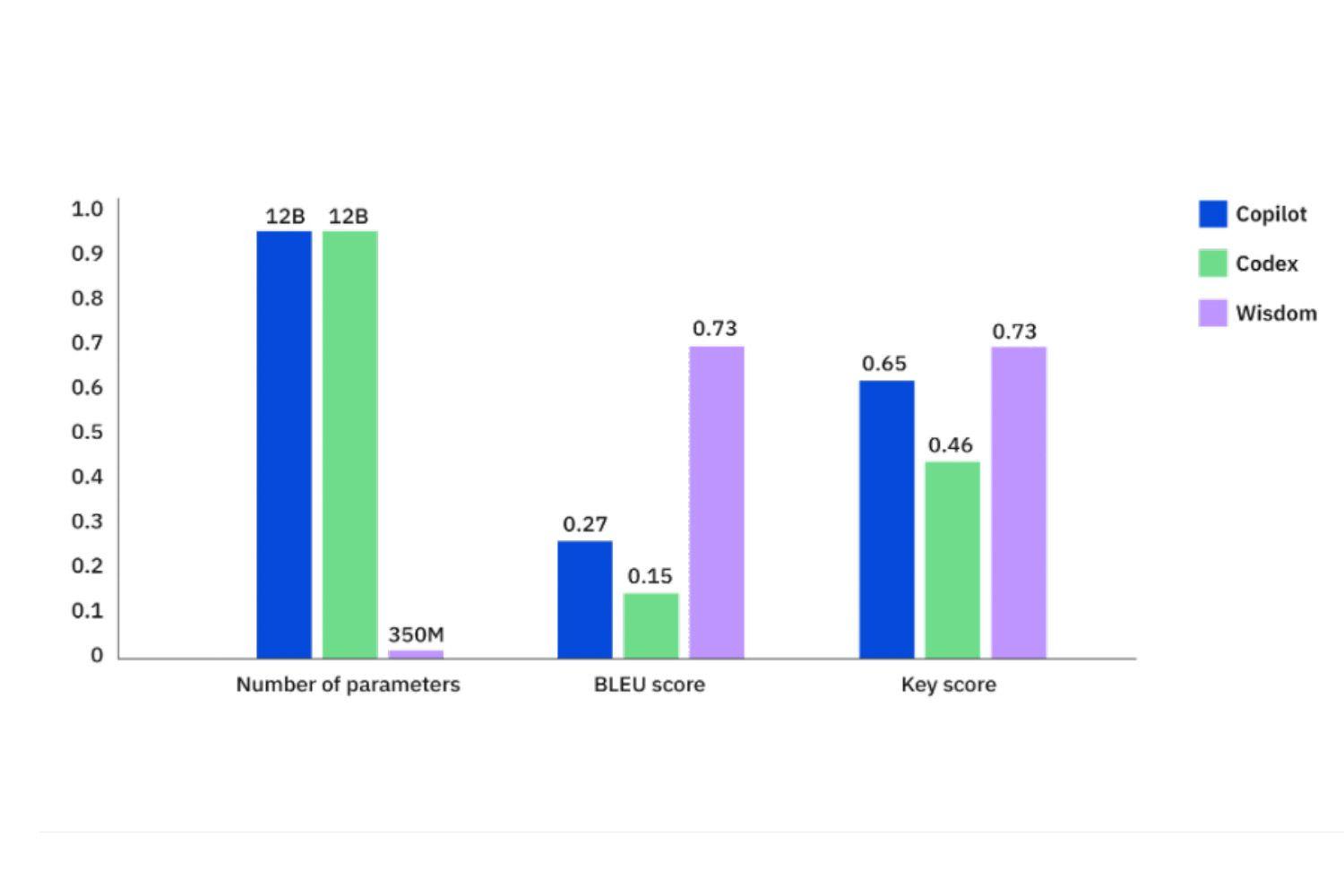
Advances like this promise to close the skills gap and boost the productivity and efficiency of developers and IT engineers. Project Wisdom addresses content generation, content discovery, and debugging. It could increase code development productivity by over 10 times. It is accessed as a feature in the Ansible extension for Visual Studio Code.
The use of large foundation models with newer, realistic benchmark datasets, challenging leaderboards, and new algorithms for document retrievers and readers have led to a lot of progress for question answering.
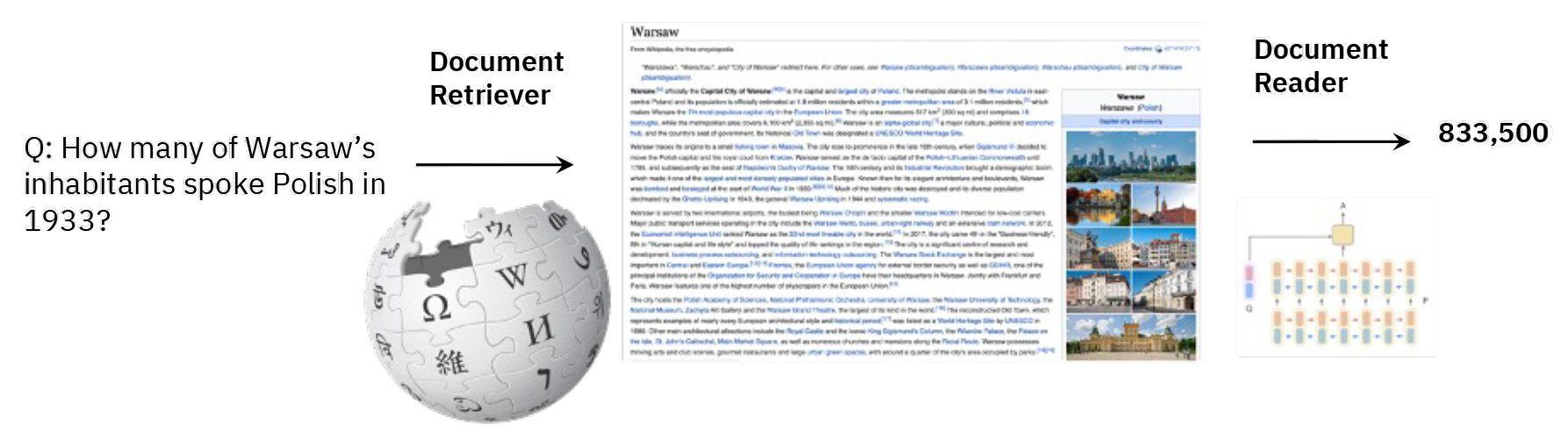
In this area, we open-sourced technology that uses foundation models for multi-lingual question answering with PrimeQA, an end-to-end toolkit that can give precise answers to English questions from any combination of languages. It spans traditional and neural retrievers, including multi-lingual retriever Dense Retrieval with Distillation-Enhanced Cross-Lingual Representation (DR.DECR). PrimeQA readers are multilingual. As the model learns the training domains via knowledge distillation, it achieves better out-of-domain generalization in question answering than popular domain generalization approaches and leads to readers that are robust on new domains. PrimeQA will also be supporting multimedia question answering over news and movies.
In building AI systems, we must also address the multi-faceted issue of trust. Otherwise, the lack of trust can render even the most powerful AI model unusable for practical deployments. This is why trustworthy AI has been at the forefront of our research agenda since 2017. We are addressing concerns like domain-shift, adversarial attacks, model uncertainty, and making AI’s decision-making process explainable. Given the diversity of AI models and technologies, and their varied applications, fairness and explainability need to be handled at different stages of the AI lifecycle and will involve different algorithms. For example, open and extensible toolkits such as Trust 360 incorporate diverse methods to support fair, explainable, robust, and safe machine learning with transparent reporting, leading to the latest enterprise AI governance solution built on IBM Cloud Pak for Data.
We are building foundation models with trust guardrails. We developed new ways to mitigate bias to improve the fairness of large models without costly retraining, and explored model reprogramming as a fairness learning paradigm. We also addressed the data pipeline — from data design to sculpting and data evaluation — for trustworthy AI.
In 2023, we will continue to advance our vision for foundation models by scaling to larger models in our OpenShift-based stack for training and validation. We will increase the number of modalities and use cases with more purpose-built foundation models, including models for IT automation, security, and geospatial data, to deliver better outcomes for domain-specific applications. We will also continue to develop more efficient hardware accelerators for AI-centric supercomputing, improving performance and energy consumption with the flexibility of end-to-end hybrid cloud.
Quantum-centric supercomputing will change what it means to compute and will deliver quantum advantage.
IBM Quantum is on a mission to bring useful quantum computing to the world and make the world quantum safe. 2022 was a pivotal year for us: We first published our roadmap for quantum computing in 2020 and last updated it in May 2022 to outline our vision of quantum-centric supercomputing. We believe quantum computers will be seamlessly integrated with classical processors and networks using hybrid cloud tools. Our roadmap today hinges heavily on modularity and middleware for quantum computing.
We increased our emphasis on performance as measured by three key metrics:
- Scale, as defined by the number of qubits
- Quality, measured by quantum volume (QV)
- Speed, or how fast our systems can solve a problem, measured by circuit layer operations per second (CLOPS).
To increase scale, we redesigned the quantum chip packaging in our Eagle processor to more efficiently bring signals to and from the superconducting qubits by using thru-substrate vias and multi-level microwave wiring technology. With the introduction of our 433-qubit processor Osprey in 2022, we added integrated filtering to reduce noise and improve stability, and increased scale by three times.

We can understand quantum volume as the biggest square circuit that we can expect to run successfully in a quantum computer. QV takes into account all performance parameters (coherence, crosstalk, measurement and initialization errors), design parameters (device connectivity and gate set), and circuit compiler quality.
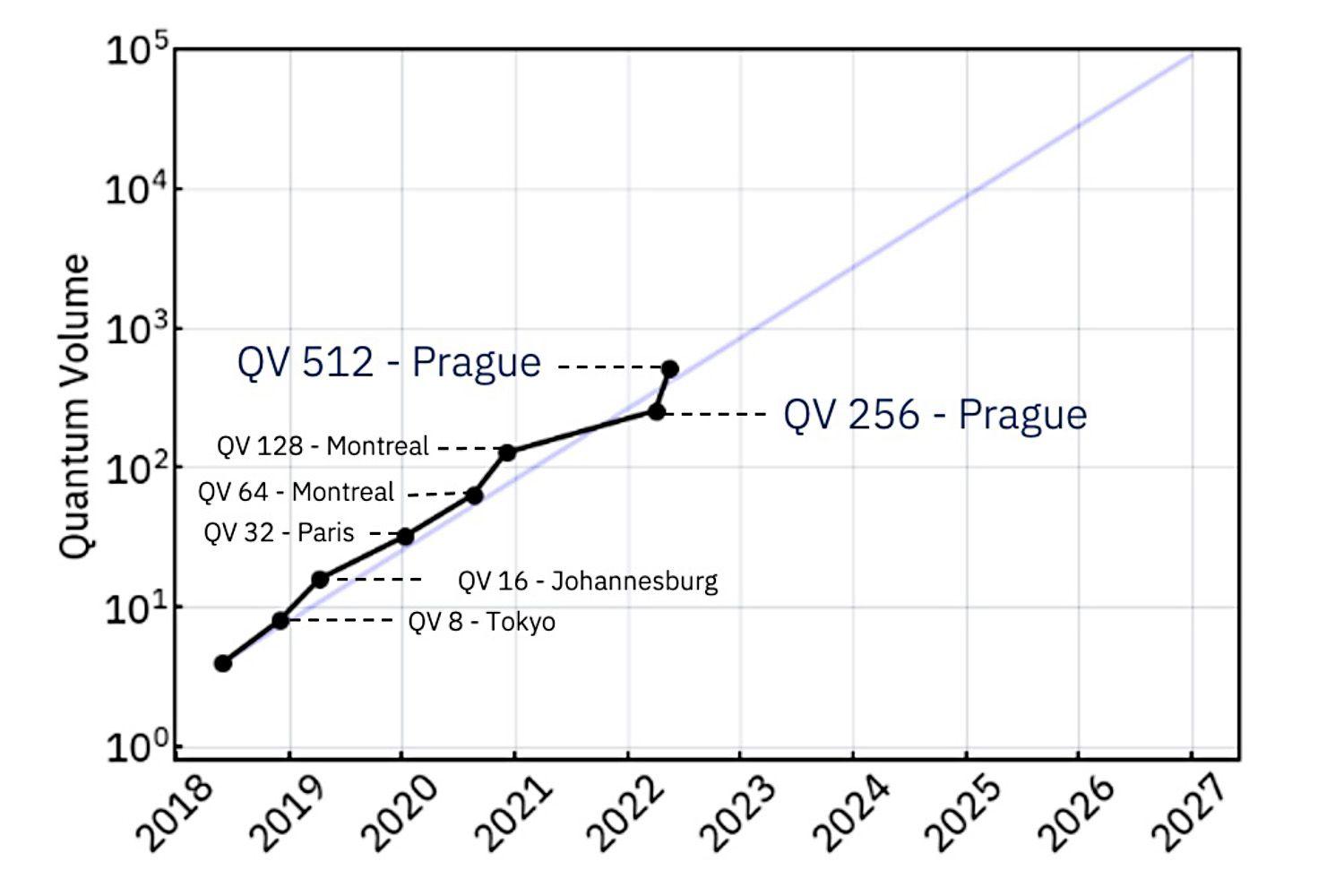
In 2022, we improved QV from 128 to 512 through faster, higher fidelity gates with the device median approaching 10-3 two-qubit gate error.
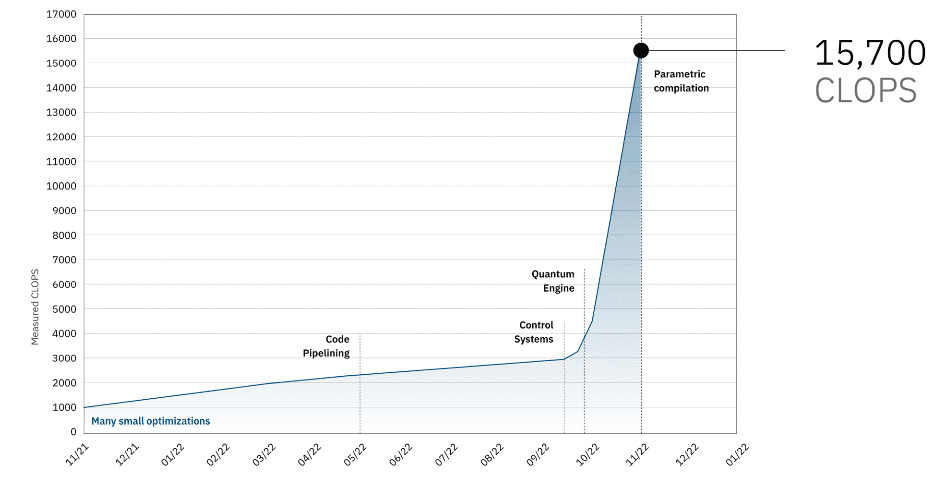
The rate at which circuits can run is another critical parameter. CLOPS, our measure of the computational speed of quantum processors, is correlated with the number of QV circuits that a quantum processing unit (QPU) can execute per unit time. In 2022, we improved our CLOPS by an order of magnitude, from 1.4K to 15.7K, through improvements to the runtime compiler, the quantum engine, and our control systems.
To be useful, performance must be coupled with advanced capabilities and integrated in a frictionless experience. To simplify application development, we launched the Qiskit Runtime primitives. These are prebuilt core functions for the tasks most relevant to applications. The primitives allow algorithm developers to build workloads more easily and efficiently without extensive knowledge of the hardware.
By setting an optimization level in the API, the primitives automatically apply error suppression to the quantum circuits using dynamical decoupling. The runtime compilation also processes the results with error mitigation, and in the future, with error correction. Since error mitigation comes at a cost in classical processing, the primitives include “resilience levels” that can be adjusted to control the tradeoff between accuracy and cost. These resilience levels go from measurement mitigation to zero noise extrapolation (ZNE) — a non-unbiased error mitigation method — to probabilistic error cancellation (PEC), an unbiased error mitigation method, with increasing sampling costs. This can all be beta tested on IBM Quantum Services.
Using ZNE, we obtained a good estimation of weight-1 observables in a 127-qubit 36-deep circuit. This is the largest quantum circuit ever run on a quantum computer. Using PEC, we demonstrated a 65-qubit 15-deep estimation of weight-10 observables, in an approach that included circuits that are beyond exact classical simulation.

Most recently, we also demonstrated the use of coherent Pauli checks for error detection and single-shot error mitigation of Clifford circuits, useful for tasks involving sampling the output distribution of quantum circuits in noisy quantum processors with limited qubit connectivity.
We also deployed dynamic circuits on 18 IBM Quantum systems. These are computational circuits that combine quantum and classical operations, using the outcome of classical computations to adapt subsequent quantum operations using feedback and feedforward. Dynamic circuits can reduce circuit depth, implement state and gate teleportation, or leverage space and time resources as in the iterative phase estimation algorithm.
Our technical breakthroughs in 2022 are starting to sketch a path towards quantum advantage in the near future. Toward this goal, we are working to build the capability of estimating noise-free observables of circuits executed on 100 qubits with depth 100 within a day by 2024. That requires close to three-nines fidelity, not far from our current Falcon R10 performance.


We are also developing a quantum-centric supercomputer, a modular computing architecture that uses quantum communication between modules and a hybrid cloud middleware to seamlessly integrate quantum and classical workflows.
Toward this end, we released an alpha version of quantum serverless in November 2022. It is software architecture and tooling that tightly integrates and manages quantum and classical computations while abstracting away the complexities to allow developers to focus only on code and not infrastructure. We also released an alpha version of what we call the circuit knitting toolbox. It involves an advanced orchestration that decomposes large quantum circuits into smaller ones, distributes the subparts for concurrent executions on available hardware, and reconstructs the quantum results using classical post-processing. Full releases for quantum serverless and circuit knitting are planned for 2023 and 2025 respectively.
In 2023, we will be connecting quantum chips with real-time classical communication. This will evolve to quantum communication links between processors to reduce execution time. We are developing the compilers and orchestration for this purpose. Further down the line, optical transduction networks will enable a fully reconfigurable quantum intranet.
To scale the I/O, we debuted cryogenic flex to replace traditional coaxial cabling, providing improvements in size and cost.

We are strategically partnering with vendors to explore modular cryostat solutions. At the same time, we have continued to reduce the size and cost of control electronics through three generations, now controlling 400 qubits with a single rack, an 80 times improvement over six years ago when a rack could control only five qubits. To continue to push on scalability and affordability, we previewed a cryogenic CMOS controller, controlling four qubits with a chip the size of a fingernail sitting at 4 Kelvin.
We will see the first IBM Quantum System Two this year. It will showcase many of our modularity designs at the I/O, control electronics, and quantum processor level. It will feature integrated classical computing resources for parallel classical communication across processors, enabling workloads hitherto unapproachable.
Improvements in theory, software, and hardware, a modular architecture that allows parallelization, along with quantum serverless integrating, orchestrating, and managing quantum and classical computations will define the near and mid-term future of quantum computing.
While we are quickly advancing the state of quantum computing, with its myriad benefits also come risks. The two encryption schemes most widely used today to safeguard sensitive data — RSA and elliptic curve cryptography — could be obsolete in a future where powerful quantum computers are available. Quantum computers this capable may still be far away, but data can be harvested and stored now, and when those machines become available, used in the future to decrypt the past. At IBM, we are committed to building revolutionary technology — and to mitigating the risks that such technology may pose. That’s why our team has been working for years to develop cryptography that future quantum computers cannot break.
We have been engaging with standards bodies to define this new quantum-safe cryptography. In July 2022, the U.S. National Institute of Standards and Technology (NIST) announced four quantum-safe algorithms for standardization, three of which were proposed by IBM researchers and their collaborators. We have started the transition ourselves, building our newest generation z16 system to be quantum-safe from the firmware up. In parallel, we launched our IBM Quantum Safe services to support our clients’ transition to quantum-safe cryptography. Quantum-safe cryptography will provide coverage and solutions in all four key aspects of security: confidentiality, identification, integrity, and repudiation.
Advances in cryptography and AI will reduce the growing cyber-attack surface area and provide decentralized security.
Security is about coping with threats, which are costly for businesses. The average data breach cost in 2022 was $4.35 million, a 12% growth in the last two years. Managing the risk of threats requires reducing the attack surface available to adversaries. This includes the surface exposed to attackers across the hybrid cloud environment, vulnerabilities and malware introduced by open-source software and third-party hardware and services, and the attack surface increase due to technological trends such as self-sovereignty and Web3 that are driving more decentralization.
We see six areas of focus to reduce the attack surface area of enterprises:
- Quantum-safe cryptography and crypto agility
- AI and threat management
- Enabling AI on encrypted data using fully homomorphic encryption
- Leveraging confidential computing for zero trust security
- Central bank digital currency
- Supply chain security: software and systems
Quantum-safe cryptography (QSC)
In May 2022, the White House released a National Security Memorandum laying out the administration’s plan for securing critical systems against these potential threats. In July, NIST selected four quantum-safe algorithms for cryptographic standardization, which they expect to finalize by 2024. In September, the National Security Agency (NSA) issued guidance setting out requirements for owners and operators of national security systems to start using quantum-safe algorithms by 2035. And in November, the US government issued directions on migrating to quantum-safe cryptography to its agencies.
In September 2022, the Global System for Mobile Communications Association (GSMA) formed a Post-Quantum Telco Network Taskforce with IBM and Vodafone as initial members. The network will help define policy, regulation, and operator business processes to make telcos quantum safe. The World Economic Forum (WEF) recently estimated that more than 20 billion digital devices will need to be either upgraded or replaced in the next 10 to 20 years to these new forms of quantum-safe encrypted communication.
To address this need, we developed a new approach, dubbed Cryptography Bill of Materials (CBOM). It describes cryptographic assets while extending existing software supply chain tooling and simplifies the creation and management of a cryptography inventory across diverse software, services, and infrastructure. It also allows complex cryptographic components to be added to well-established tools and processes to assess software supply chain security and integrity.
Our approach prioritizes the creation of a cryptography inventory, analyzes the root cause of vulnerabilities and provides migration recommendations, upgrades to quantum-safe cryptography, and simplifies the creation and management of a cryptography inventory. We started with our own products: IBM Cloud Cryptography Services and IBM z16 systems are already quantum safe.
AI and threat management
Security operations teams must minimize the time from an initial security breach to mitigation of the impact if the breach is successful. We are building tools for automated threat detection, investigation, and response. This includes proactively profiling and hardening workloads, and policies that provide high-confidence detection capabilities. In addition, deep instrumentation of workloads, systems, and platforms help collect and analyze activities in the cloud. Combining these rich data sources with trusted advisors and automated tools, we will be able to triage incidents, reason across them, generate threat hypotheses, and recommend orchestrated responses.
Given the increasing sophistication of threat actors and their ability to imitate normal network behavior, we need new and more robust approaches to analyze network traffic to detect suspicious activities and breaches. The latest network traffic analysis solutions combine machine learning, advanced analytics, and rule engines to detect suspicious activities on enterprise networks at high scale. We built the Security Network Threat Analytics Application (NTA) for QRadar to help organizations better counter network threats. It leverages the latest machine learning techniques and includes novel technology for high-performance analytics of network flows on the edge.
We have continued advancing SysFlow, a runtime observability framework that makes security-related data science tasks easy. Its open telemetry format records how processes, containers, and Kubernetes pods interact with their environment and builds stateful system behavioral graphs from streaming data. This provides important context for security analysis. SysFlow can collect system events using eBPF. It uses the CNCF Falco libraries to collect system events for downstream tasks, including real-time analysis through a stream analytics pipeline that accepts user-defined plugins, tags telemetry records with MITRE TTPs, and exports events to storage and analytic backends. In 2022, SysFlow became the basis of IBM ReaQta ’s endpoint security agent for Linux. SysFlow enhances ReaQta with a lightweight layer that brings observability into Linux endpoints.
We invented, designed, and developed a solution for automatic investigation of cyber threats. The algorithm starts from a set of disconnected attack signals and iteratively connects and expands them into a comprehensive, insightful attack graph to expand knowledge and intent of a cyber-attack and help better assess it. It is now part of the IBM Security QRadar XDR suite. It includes analytics, an orchestration engine, content and user interface, alert correlation algorithmics, and open-source contributions. This technology aims to make security operations center analysts more efficient.
We are making cyber reasoning and threat discovery faster and easier with Kestrel threat hunting language — our new open-source programming language for threat hunting. Kestrel uses Structured Threat Information Expression (STIX), an open-standard for expressing and exchanging cyber threat data and intelligence. Kestrel runs on top of STIX-Shifter, another open-source project by IBM Security, to automatically compile threat-hunting steps down to the native languages that the different data sources speak and execute. Beyond patterns, Kestrel abstracts hunting knowledge codified in analytics and hunting flows. Kestrel is integrated into Data Explorer, which is part of IBM’s Cloud Pak for Security.
In June 2022, we participated in hackathons at the Cybersecurity Automation Workshop, where we integrated new SBOMs (software bill of materials) into Kestrel, and integrated Kestrel with the OpenC2 standard. This was later presented at BlackHat Arsenal. The community has started to embrace Kestrel. It is now integrated into the Cacao playbook standard. We have also developed a response framework, called Tzu, under the DARPA’s Cyber Threat Hunting at Scale (CHASE) program. It can be used to automate threat response.
We are working on key data privacy capabilities for AI training data and addressing the growing need for optimized and efficient data classification for structured data. Our data privacy protection technology, incorporated in WKC AutoPrivacy, will be released as part of Data Virtualization and Guardium this year. It allows to mask personal and sensitive data while allowing downstream processing and preserving referential integrity. We developed technologies like format classification and fuzzy matching that can efficiently, in near real time, classify hundreds of millions of columns in multiple distributed databases. This technology will be released early this year as part of Cloud Pak for Data.
We are also developing technologies that can protect AI applications and services from adversarial attacks. The open-source Adversarial Robustness Toolbox (ART) was awarded in February 2022 the unique status of Graduate Project of the Linux Foundation AI & Data, a key milestone in establishing ART as a vendor-neutral open standard for adversarial machine learning. We developed and open-sourced the Universal Robustness Evaluation Toolkit (URET) to provide tools for evaluating evasion in datasets that contain categorical and string data. We also created the first version of the extension library to provide tools for robustness and privacy evaluations with Watson Core.
We developed and open sourced the AI Privacy 360 Toolbox to support the assessment of privacy risks of AI-based solutions, and help them adhere to privacy requirements. Its anonymization module contains methods for anonymizing machine learning model training data, so that when a model is retrained on the anonymized data, the model itself will also be considered anonymous. The minimization module contains methods to help adhere to the data minimization principle in GDPR for machine learning models. A new web-based demo is available. We also built Diffprivlib, a general-purpose library for experimenting with, investigating, and developing applications using differential privacy.
In 2023, we will enable secure and trustworthy, reusable, and flexible AI foundation models. We will make AI governance more robust, focus mainly on privacy risk assessment of AI models, and extend our security capabilities to new modalities and additional privacy metrics. We will add capabilities for assessing privacy risks in synthetic data and continue our work on data minimization and unlearning.
Enabling AI on encrypted data using fully homomorphic encryption (FHE)
As part of our work to develop efficient schemes and implementations of libraries supporting fully homomorphic encryption, IBM was the first to develop an FHE library for use by the security community. We are now building a development framework that can be used for applications, IBM HElayers. It is designed to enable application developers and data scientists to seamlessly apply advanced privacy-preserving techniques focused around FHE, but also supporting secure multi-party computation (sMPC) and other cryptographic methods, without requiring specialized skills in cryptography. It provides both Python and C++ APIs and can be used to develop applications for x86, IBM Z, and IBM LinuxONE.
We can do data exploration over encrypted data. We can also train a machine learning model across multiple decentralized parties holding local data sets— without sharing the local datasets. This allows building a collective machine learning model without sharing data between the parties. A demonstration of HElayers in a federated learning scenario is available in a Jupyter notebook. HElayers is now available in Watson Studio and IBM Cloud Pak for Data.
We demonstrated an approach that enables formal privacy guarantees on training data while enterprises train collaboratively, and protects output privacy during inference. The entire stack is designed to be efficient and scalable. We also built a cloud-hosted service that enables data scientists and developers to deploy privacy-preserving machine learning SaaS applications in the cloud.
Harnessing FHE and other cryptographic methods to enable privacy-preserving technologies and AI on encrypted data is central to our research. We continue to advance the use of FHE, making it more practical, and developing its applications.
Leveraging confidential computing for zero trust security
When running workloads on multiple clouds, we face an expanded attack surface, a multiplicity of cloud stacks, and multiple actors involved in securing the workloads. When clouds span geographies or industries, regulatory and sovereignty requirements make things more complex. We are addressing these challenges by advancing foundational security technologies across three areas—system integrity, confidential computing, and adaptive policies.
To improve system integrity, we have been working with Red Hat and the Linux community to advance the Integrity Measurement Architecture (IMA). IMA, which is part of the Linux kernel, can detect if files have been accidentally or maliciously altered. Red Hat Enterprise Linux 9 (RHEL9)-based deployments can now use IMA at the kernel level to verify the integrity of files and their provenance. We are actively working with the community to extend IMA to protect containers, enforcing the signature of all executables inside a container with an appropriate key. An integrity monitoring solution, such as Keylime, may also be used to determine that only trusted executables have been started inside a container. An IMA namespace may also use an attached virtual Trusted Platform Module (TPM) in the same way as IMA on the host uses the hardware.
We are advancing confidential computing to improve the isolation capabilities of host systems. Working with the open source community, we are enabling confidential computing for containers, leveraging Trusted Execution Environments (TEEs) to protect container workloads using confidential virtual machines (VMs). For instance, the TEE technology in IBM Z systems is called Secure Execution (SE). By establishing a secure connect from an SE VM to the IBM Hardware Security Module (HSM), we assure confidentiality while still meeting cloud infrastructure requirements for scalability.
Confidential computing protects a program from external attacks. We have also developed memory safety protection mechanisms to protect a program from internal attacks like buffer overflow and heap memory vulnerabilities. We implemented a runtime mechanism to mitigate the heap memory vulnerability in the kernel while a more permanent fix is in the works.
We follow an adaptive, policy-driven approach based on the zero trust principles of least privilege and continuous verification. We analyze real time context like IMA signatures and risk and vulnerability assessments to derive proactive measures to secure cloud workloads. We automate policy reasoning and derivation based on a client’s cloud context, incorporating compliance requirements with applicable security standards. This allows us to derive dynamic Open Policy Agent (OPA) policies. Our approach has identified security and privacy challenges in popular applications and cloud services. These policies drive cloud isolation and protection capabilities, changing how containers are placed within cloud deployments to reduce their attack surface. Containers with similar security metrics are collocated, and the placements of containers is adjusted based on changing workload mix and user policies. We are working with the container community to upstream this new capability.
Central bank digital currency
Central bank digital currency (CBDC), a digital system for managing wholesale financial assets and legal tender for retail payments, is a topic of exploration of central banks globally. To date, more than 80 central banks have announced different levels of technology experimentations on CBDC infrastructure. The European Commission issued a public tender on a digital Euro front-end. The White House issued an executive order on the secure implementation of digital assets and CBDCs.
The digital management of regulated assets is challenging, due to the complexity of combining privacy with regulation compliance and the scalability, performance, and resilience of the resulting systems to compromised nodes. If a variety of CBDC infrastructures is adopted, they would also need to harmonically co-exist and interoperate. We worked with a consortium led by HSBC and another one led by Euroclear to build a framework that copes with these challenges in response to the Bank of France Call for Experimentation on CBDC. These experiments (e.g., cross-system bonds trade and coupon payment) were implemented on Hyperledger Fabric using the associated token and interoperability components that we developed. The token framework leverages zero knowledge proofs for privacy, making the transaction details accessible solely to transaction participants unless an audit is needed. The interoperability framework allows shaping assets across different CBDC systems, or across CBDC systems and legacy systems.
Software supply chain security
Much of the world’s infrastructure relies on open-source software across the entire stack, from infrastructure to operating systems, compilers, middleware, and applications. Every aspect of the development and build process must be trusted. A recent White House executive order on improving the nation’s cybersecurity explicitly called out supply chain risks and the need for a software bill of materials (SBOM).
We have been developing technologies to analyze source and binary code at multiple levels of granularity, called code genome. Just like the human genome is our genetic blueprint, this technology can help identify the building blocks of the software supply chain to better secure it from cyberattacks and vulnerabilities in unpatched software. The technology successfully identified difficult to detect instances of the Log4J vulnerabilities. The information from the code genome can be used to build SBOMs by analyzing the composition of software even for legacy code for which no source code is available. A technology preview was recently presented to the Linux Foundation and the Open Source Security Foundation. We are working on a public service for developers and other practitioners to scan and analyze their code.
We also built a platform for Automatic Breach and Attack Simulation (ABAS) to train machine learning-based detection systems by gamifying the training process. It can simulate phishing attacks, malware attacks on endpoints, data exfiltration, and sophisticated advanced persistent threats employing lateral movement. For this, we demonstrated a reinforcement learning-based attacker capable of creating a simple multi-step scenario, exploiting a known vulnerability, and breaking in a basic web service. To protect the lower levels of the stack, we are automating vulnerability exploitation classification on the Linux kernel, discovering new microarchitectural attacks, and designing new tools to assist with the discovery and analysis of the emergent class of speculative execution attacks.
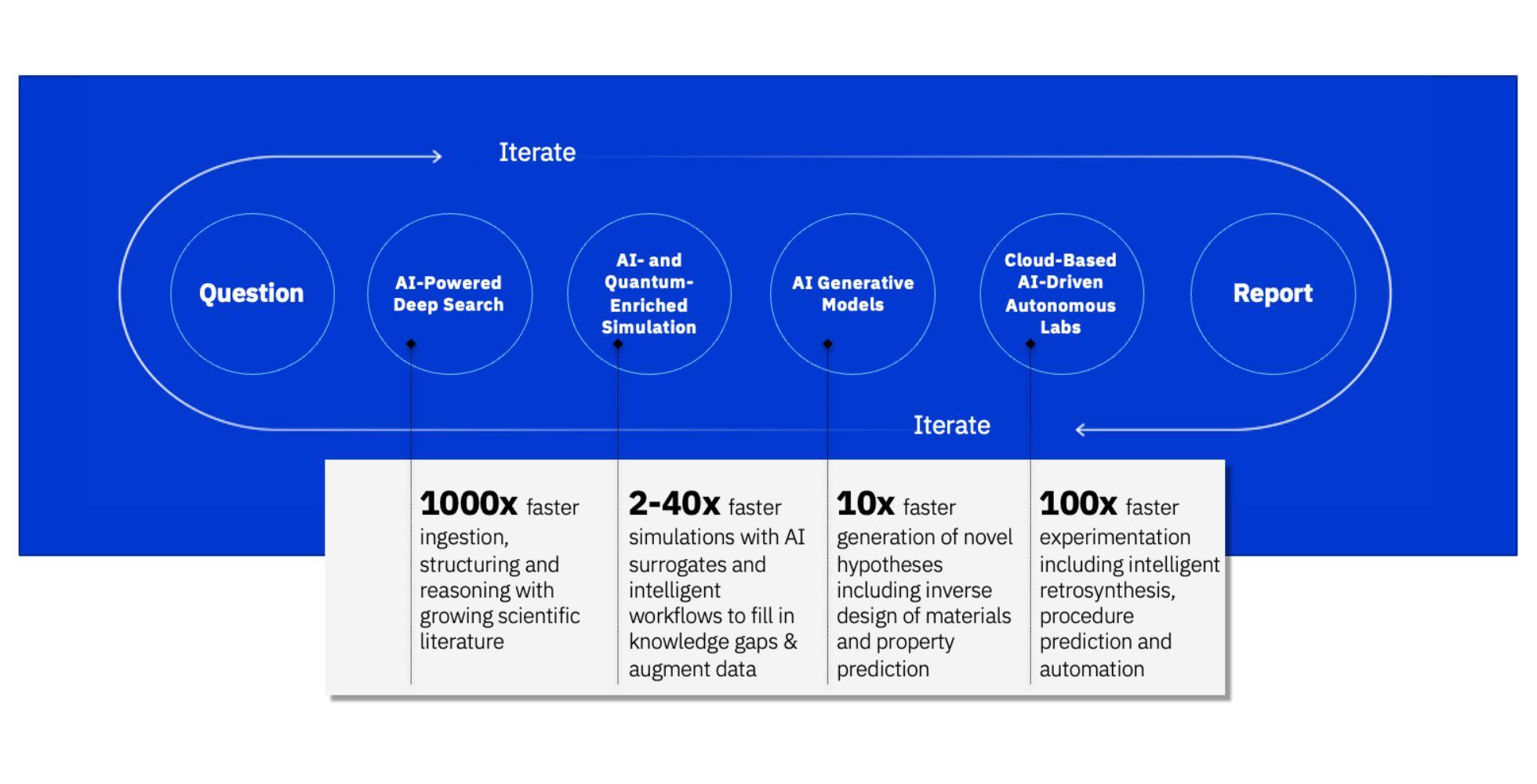
As powerful as semiconductors, AI, hybrid cloud, quantum computing, and security are by themselves, we see the highest impact in their convergence. We are using our deep expertise in these areas together with data science, data protection and governance, and our diverse domain expertise to build a powerful computing platform that we believe will enable us to tackle questions once thought out of reach. With it, we are aiming to address society’s most challenging problems, those so daunting and yet so pressing that solutions simply cannot wait. The need to accelerate the discovery process for solutions to these types of problems led us to create our new accelerated discovery platform. It is designed to enable scientific knowledge integration, advanced modeling and simulation, hypothesis generation and experimentation, and end-to-end solution discovery workflows. It will include tools, content, acceleration libraries, cross-cloud compute and data infrastructure management across cloud environments, and have simple consumable interfaces for scientific end-users.
On the path to building this platform, we have integrated our AI tools for knowledge extraction with the physics-based simulations and deep learning surrogates in our newly released open source toolkit for simulations (which we call ST4SD), and the multi-modal and multi-task generative models in our Generative Toolkit for Scientific Discovery (or GT4SD). Combining these with our cloud-based lab automations, we can accelerate the discovery of new materials, drugs — and more.
We developed a deep search experience that uses our fully automatic document conversion service to allow the interactive upload of documents and inspection of a document’s conversion quality. Documents can also be uploaded and converted in bulk with the deepsearch-toolkit. We also created DocLayNet, a large human-annotated dataset for document-layout analysis. GT4SD, first released in February 2022, focuses on material science and supports more than 25 pretrained models for material design. The library received an IEEE Open Software Services Award in July.
We initially applied these technologies — AI, simulations, and experimental automation — to the development of more sustainable photoacid generators (PAGs) for chemically amplified photoresists. Now, we are applying this approach to three main areas: computing and nanotechnology to create materials, climate and sustainability to help companies transition to low-carbon and carbon-capture strategies, and drug discovery to build models for more effective therapeutics and detect biomarkers for more personalized treatments.
In applying accelerated discovery tools to computing and nanotechnology, we focused on the challenge of replacing fluorinated organic materials, like perfluoroalkyl and polyfluoroalkyl substances (PFAS), with more sustainable alternatives. We are leading a broad academic-industry consortium to develop data and tools to accelerate the design of environmentally sustainable chemicals, materials, and processes. More generally, we are advancing the application-level integration of foundational accelerated discovery technologies into a coherent, orchestrated, flexible workbench to support the end-to-end discovery of novel functional materials. It includes generative models, dataset triage, molecule adjudication, and risk assessment.
For climate and sustainability, we created an accelerated discovery toolkit that analyzes thousands of nanopore structures and simulates their carbon dioxide uptake with automated molecular dynamics simulation. We used the results to optimize the carbon capture-and-release cycle at process scale. We developed a carbon performance engine, now included in IBM’s Environmental Intelligence Suite, which has been highlighted in Forbes, and in the HFS consulting report on carbon management technology, among others.

We also created an open science data framework to test simulation assumptions such as force field parameters for their influence on the overall simulation outcome. The framework provides an advantage for training convolutional graph neural networks that rank-order materials with regards to their CO2 performance, eventually replacing time-consuming physics-based simulations.
Another example is Geolab, which accelerates the discovery of geospatial information for the development of climate adaptation and mitigation solutions. This includes hazard mapping and prediction, renewables energy forecasting, and high-resolution greenhouse gas monitoring and management.

Geolab was announced at COP 27 as the enabling technology for the African Risk Capacity Agency to improve the response of African governments to extreme weather events and natural disasters. Powered by Geolab, we will soon launch the Climate Network, a distributed network of geospatial systems that enables large-scale federated querying, learning, and modeling across a network of Geolab nodes operated independently by member organizations.
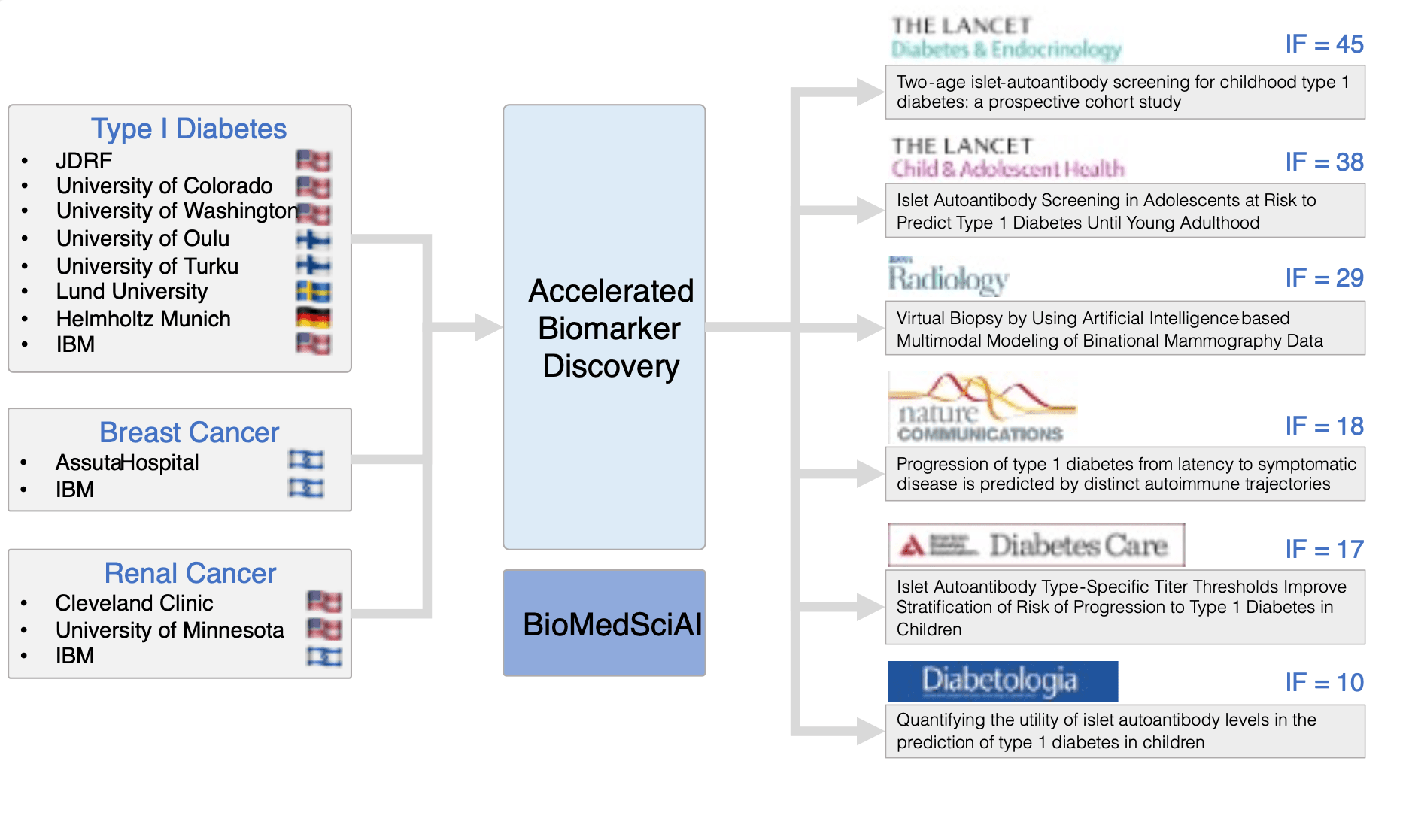
In drug discovery, one of the first biomedical projects in the IBM-Cleveland Clinic Discovery Accelerator works at the intersection of AI and hybrid cloud to develop next-generation cancer immunotherapies. The work yielded a threefold acceleration of sequence-space sampling for tailored immune cell receptors binding optimization in a simulated design procedure. The combination of AI and hybrid cloud in accelerated discovery tools has also led to new clinical insights on how novel biomarkers can be used to improve the understanding, screening, and prediction of type 1 diabetes. It is also enabling IBM and Boston Scientific to work on addressing chronic pain. By integrating imaging and clinical information into AI models, we could automatically find the stage of breast cancer in patients. We are making these technologies available in the BiomedSciAI repository.
We can use graphs in an architecture that uses machine learning and molecular dynamics to combine chemical and dynamical information for intermolecular complex generation (in the top of the graphic below). We used this tool to generate protein-peptide complexes (bottom).
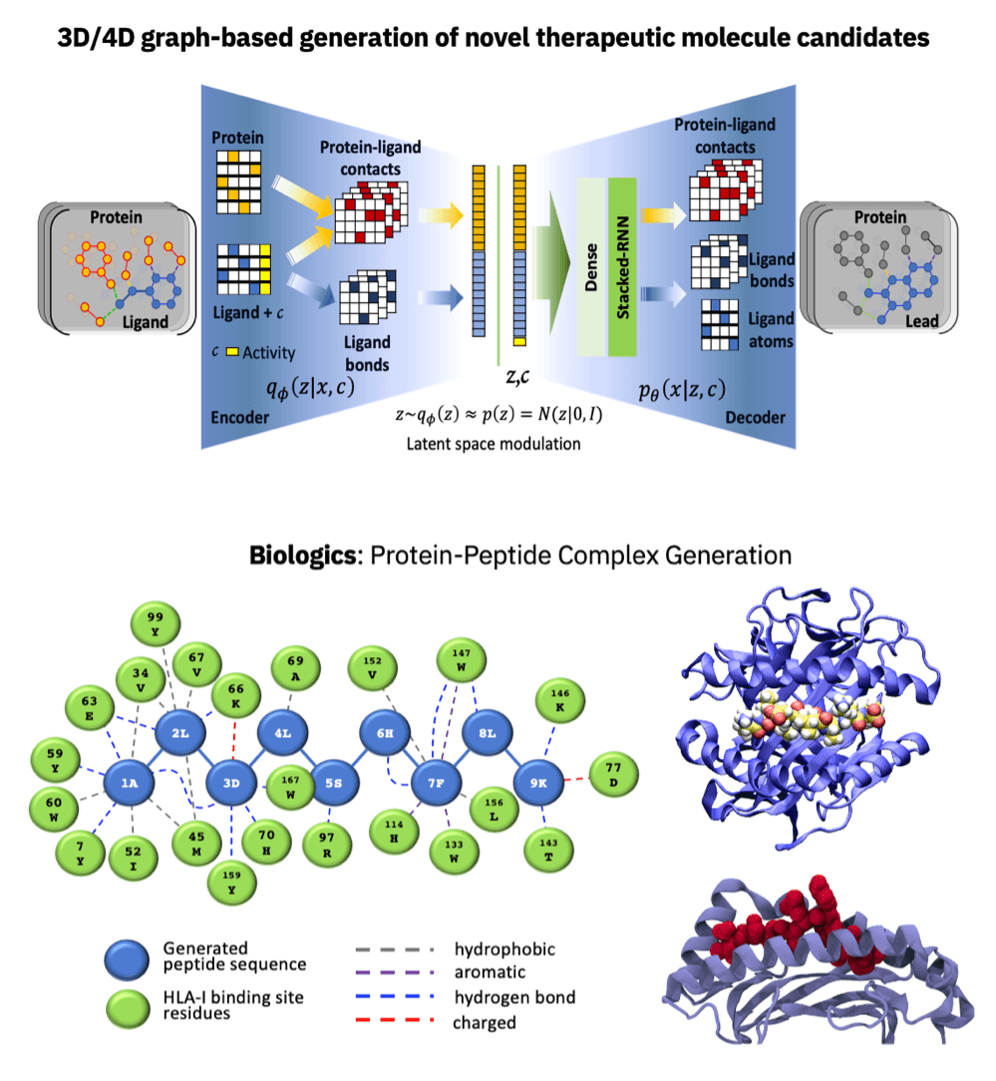
We advance all our core technologies — AI, hybrid cloud, quantum computing, security, semiconductors, and systems — guided by well-defined roadmaps. These maps are extremely valuable in stating outcomes and aligning efforts, they allow us to work more efficiently to accelerate progress. But we are also placing big bets on exploratory research to develop breakthroughs that could lead to outsized returns and transformational impact for IBM — and the world.
At the intersection of AI, hybrid cloud, and systems is a project that is creating the future of intelligent cloud storage, targeting a market predicted to reach $297.5 billion by 2027. IBM Spectrum Discover provides a single data lake house to aggregate and derive intelligence from unstructured data. At IBM Research, we are using a bio-inspired computational model derived from the hippocampal memory system in the brain and implemented using a novel multimodal neuro AI, to build a new metadata management infrastructure and advanced querying mechanism on top of Spectrum Discover. This makes it easy to find content using ad hoc natural language queries.
Bio-inspired search captures the intention in the query better showing both high precision and flexible recall over conventional database and neural IR methods to ad hoc queries. The computational model also has resulted in a new bio-inspired approach to compression called Hopfield Encoding Networks and a new embedded deduplication method leading to lowering storage size requirements by more than 50%.

At the intersection of AI and systems, we are exploring neuro-symbolic computing workloads to circumvent the von Neumann bottleneck and save computational time and energy without significant loss in precision or accuracy. We developed a novel neuro-vector-symbolic architecture for some AI workloads, such as analog computing. Our few-shot class-incremental learning requires few training samples, a memory footprint that grows only linearly with the number of classes, and constant computational cost of learning a new class. It allowed the first on-chip continual learning demonstration based on an in-memory computing realization.
In the coming years, we plan to investigate methods to combine deep neural nets with vector-symbolic architectures in a unified framework. This will allow us to build efficient learning systems based on composable distributed representations and in-memory computing substrates that will be more data- and compute-efficient.
By formalizing machine learning algorithms using automated theorem proving, we are aiming to reduce the intensive human labor cost in writing and checking machine learning code, and increase confidence that security and safety errors that can potentially compromise modern software systems will not pose significant risk. We coded and verified the general Dvoretzky stochastic approximation theorem, which underlies various forms of stochastic optimization algorithms. We will expand our formalization of machine learning library with additional algorithms, each with formal correctness guarantees.
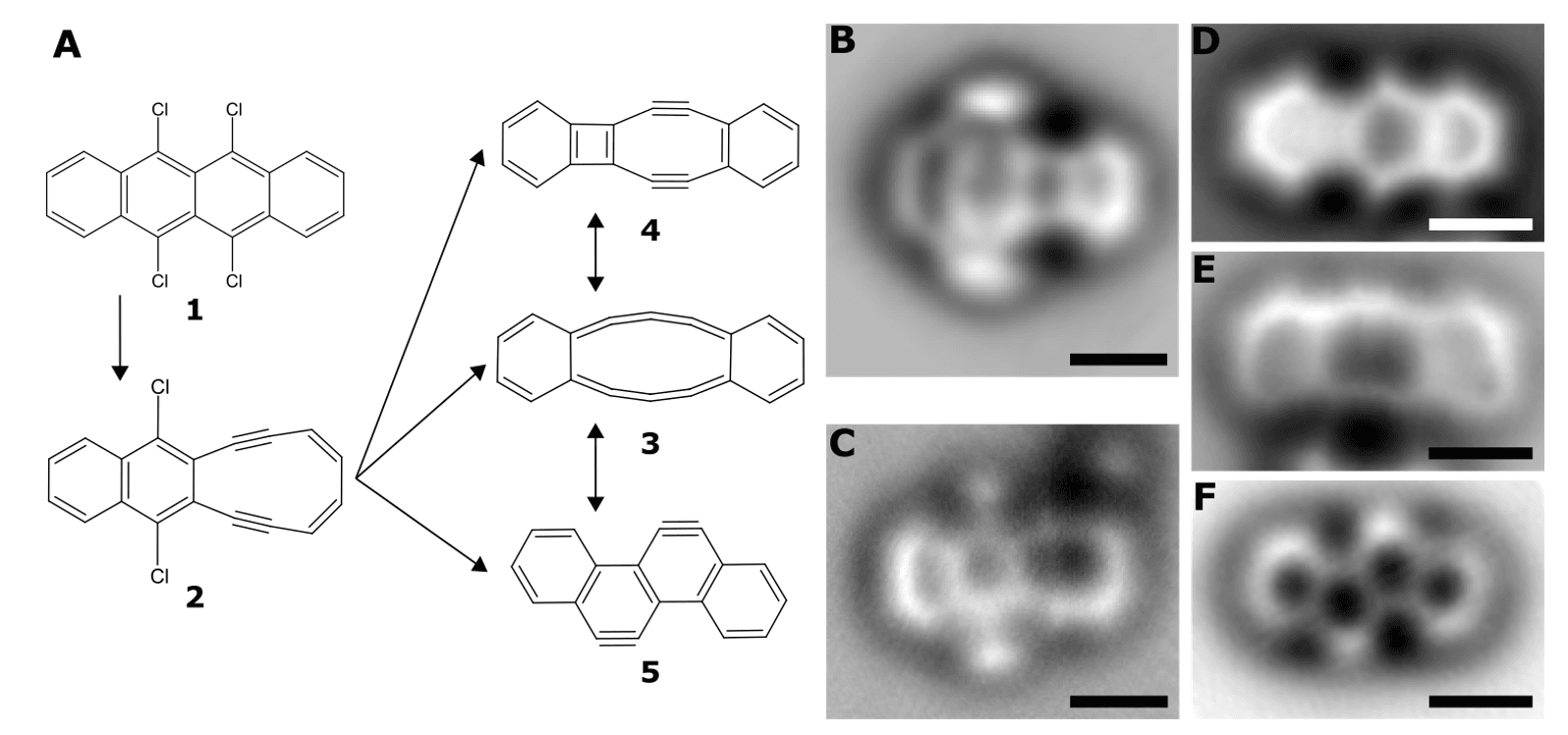
We are developing innovations with the potential for profound impact on our semiconductor roadmap. We achieved completely selective chemistry in tip-induced redox reactions using scanning probe microscopy. This was featured on the cover of Science. The work helps us to better understand redox reactions and molecular transformations. It could lead to more advanced and controllable chemical processing. We plan to expand this work to design artificial molecular machines with the potential to perform more sophisticated nano-scale tasks.
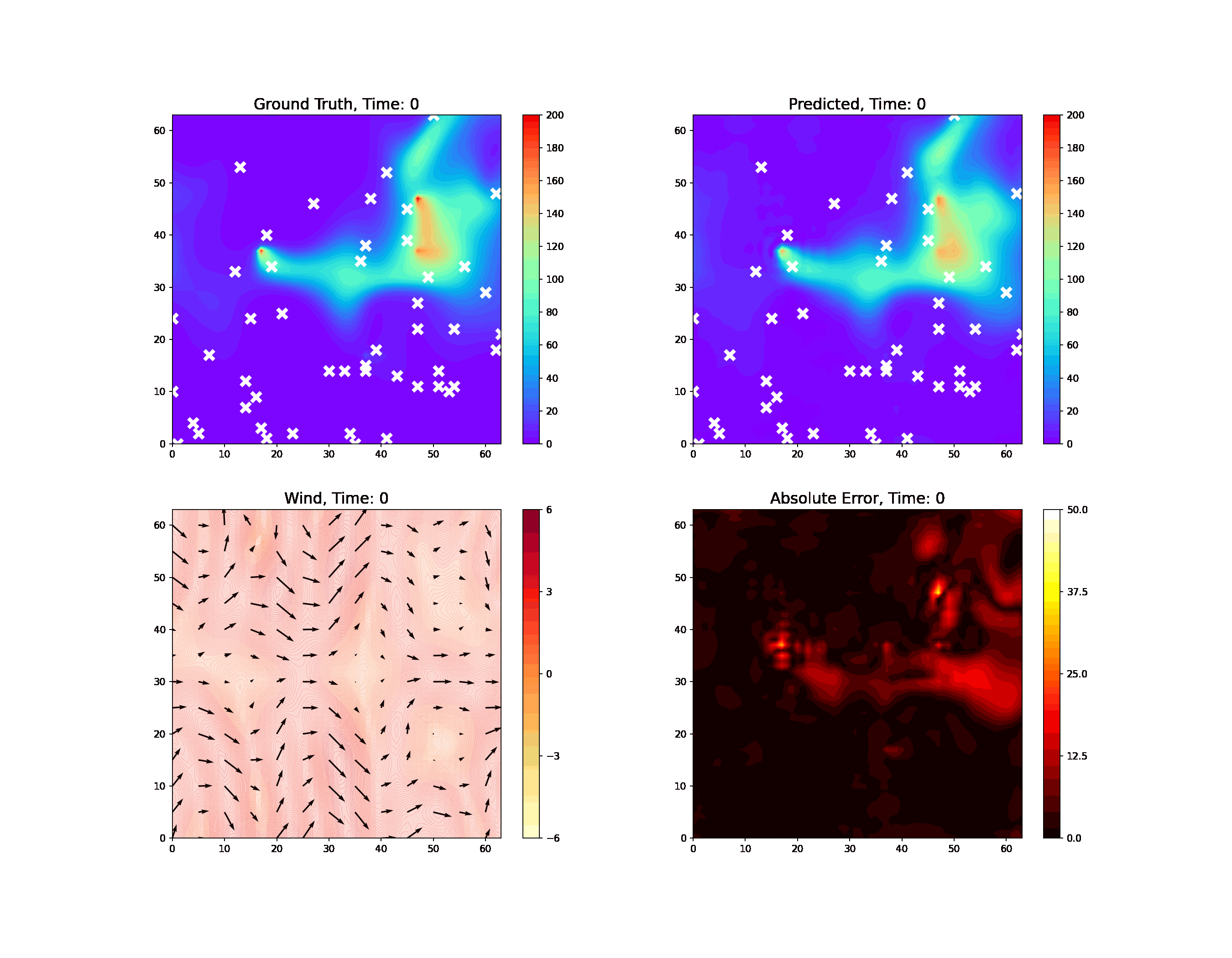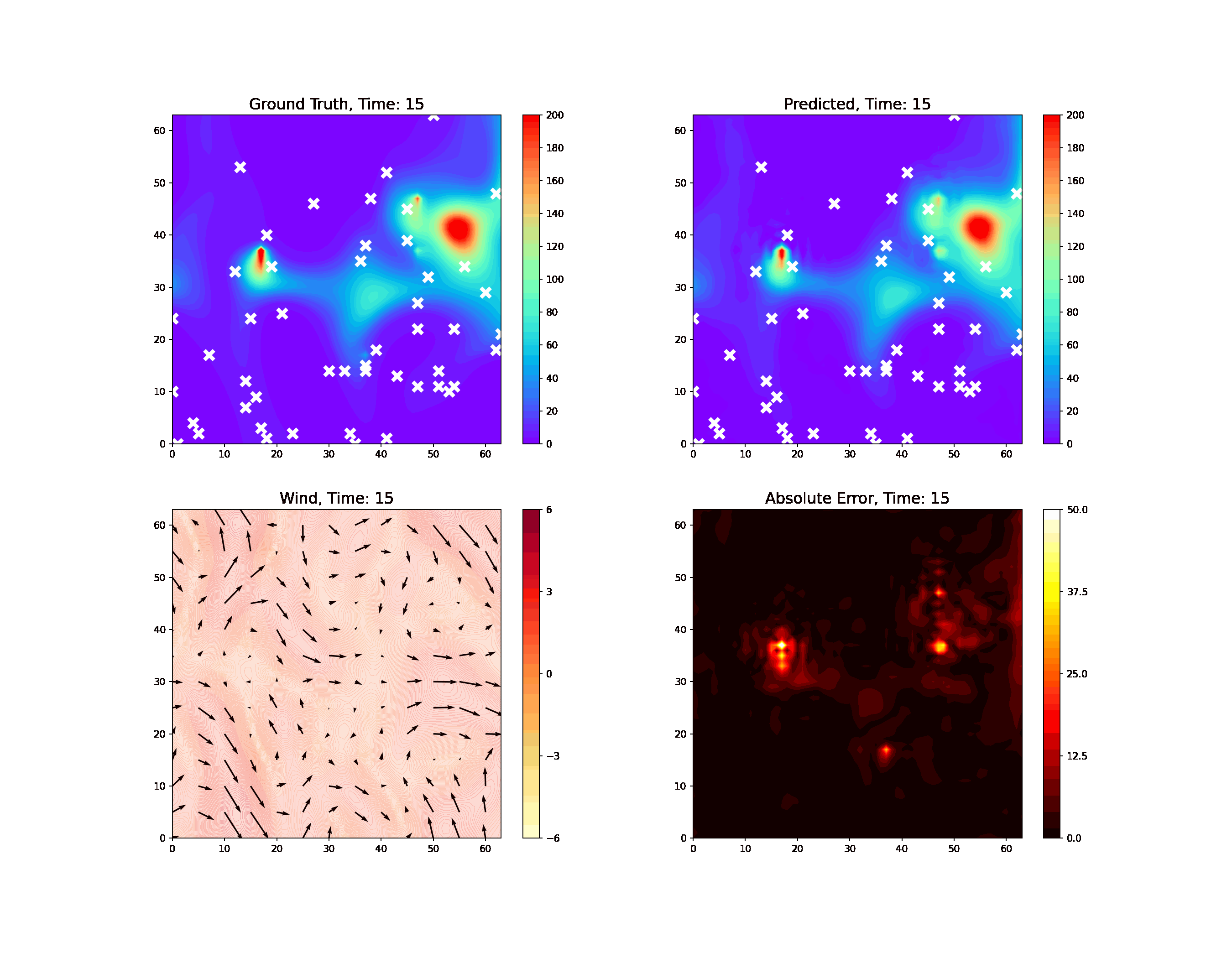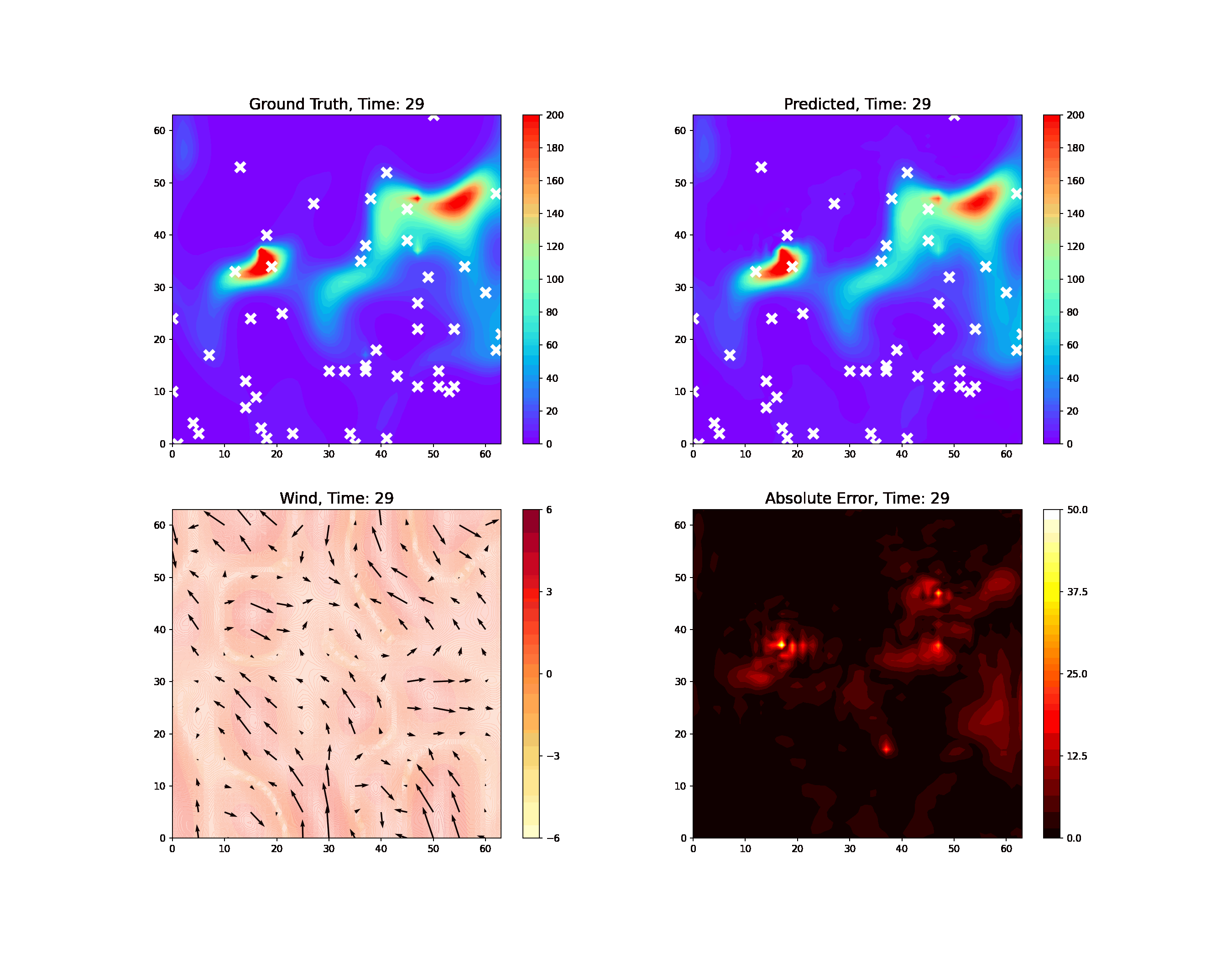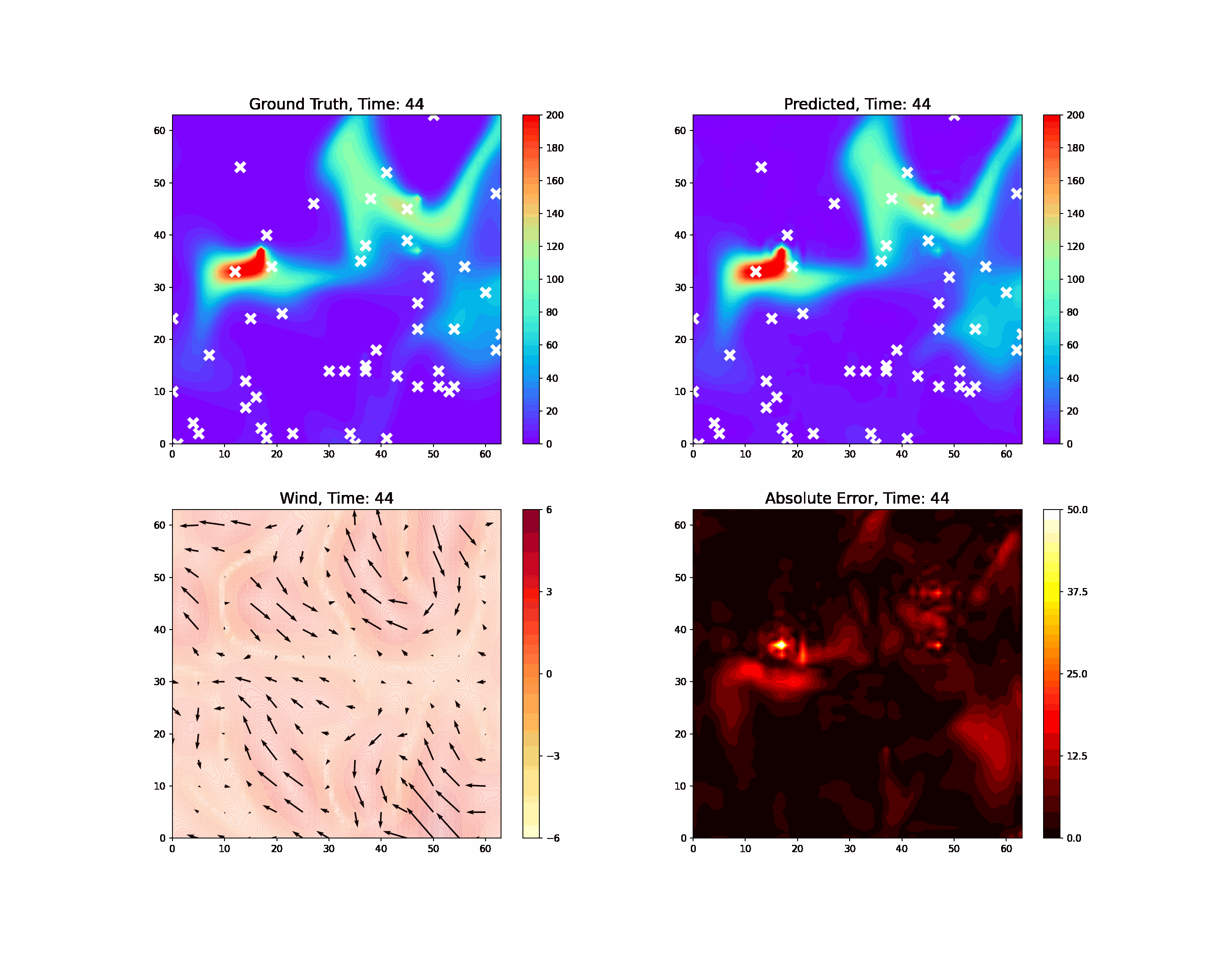
Using physics-informed AI, we have been able to improve the resolution and reliability of models of important atmospheric phenomena derived from large sets of satellite data. This led to much more accurate estimates of the location of methane leaks within the satellite data. Over the next few years, we will be integrating physics constraints in AI to enforce explainability and interpretability of neural network models while significantly accelerating computation with less data and faster training.
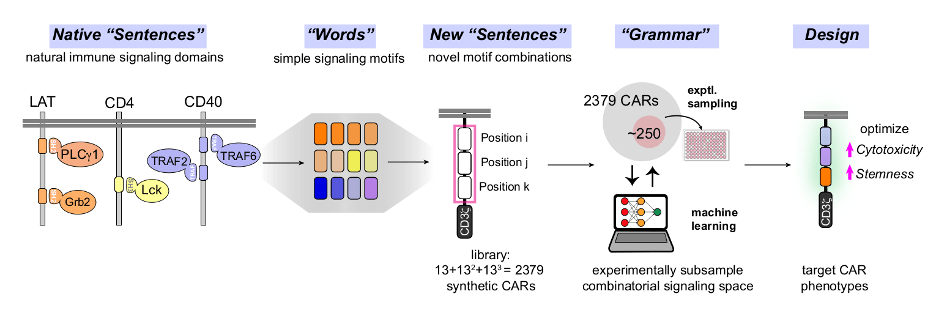
We are working with several life science partners to create computational methodologies and workflows at the intersection of AI and hybrid cloud for accelerating discoveries in the health care and life sciences. An example is the AI-driven engineering of immune system responses, where libraries built from minimal building blocks of signaling, combined with machine learning, can be applied to the design of effective therapeutic cells.
At IBM Research, we are continuously building a pipeline of innovations for IBM, our partners, and the world. We have a culture of science grounded in fundamentals, one that is agile enough to evolve in response to scientific and technological advances. We have created a culture of roadmaps that defines meaningful outcomes measured by consistent metrics to drive progress, establish timeframes, and assess risks in developing and introducing innovations. Our roadmaps lay out the path, help us build essential interdependencies, empower our researchers, and help us align our teams to work more efficiently in the directions we see most fruitful. Guided by them, we are inventing breakthrough technologies through fundamental research, tackling challenging problems with enduring impact, and advancing powerful technologies that define what’s next in computing.
We believe that what’s next in computing is the integration of highly specialized computing systems, like CPU-centric, AI-centric, and quantum-centric supercomputing. Each will be optimized across the stack to meet the needs of workflows (including combinations of computation, storage, and networking) and to maximize the speed and quality of solutions across a wide variety of applications. Combined with a hybrid cloud software stack — and a secure and efficient data fabric that makes it easy to discover and use the right data for the right task at the right location — they will form a new computing platform.
This platform will allow users to compose services and applications from the best vendors and access advanced geographically distributed computing resources from a single control plane. It will allow specialized computations to be brought to wherever data and applications are located (physical, virtual locations, or some combination of both) with robust layers of security and compliance and increasing energy-efficiency. Innovations in middleware will eliminate manually stitching modeling tools with AI and data analytics, and inefficient data exchange that rises costs. They will streamline resource orchestration, and automatically optimize workflow deployment, management, and scaling on-premises, as well as at external cloud data centers and the edge. All of this will be done while minimizing user involvement and providing a consistent user experience — no matter where an application is executed.
As we continue our journey, we will keep integrating the latest AI and quantum computing innovations into the platform to solve previously unsolvable problems and continue to increase the scale, quality, speed, and energy efficiency of computation. We aim to do all this while simplifying the computing experience for the user.
You log in or turn your computing console on, bring your problem to the console, give the computer time to understand the environment that it’s in, orchestrate everything, frictionlessly compose from the best possible services and resources — classical or quantum — and your solution is ready to use. To us at IBM Research, this is what’s next in computing.
This is the future, built right. We look forward to creating it with you.