Last year, we released the first IBM Research annual letter, with the goal of highlighting the extraordinary body of work that is the foundation of what’s next in computing. Now, we’re back after an even bigger year. In this letter, beyond just laying out our technical achievements from 2023, we want to show how our engine of research and development is leading to commercial products for IBM and impactful results for our clients faster than ever before.
IBM Research has been at the forefront of computing, pushing technology forward for nearly 80 years now. Just in 2023, we unveiled the new Quantum System Two that we believe will be indispensable for the future of quantum-centric supercomputing, designed and incubated watsonx, IBM’s new AI and data platform for enterprises, and pioneered several new semiconductor designs that could revolutionize how the world computes. We designed a cloud-native AI supercomputer with IBM Cloud, worked with Red Hat to power the future of enterprise AI, and teamed up with the likes of NASA, the UK’s Science and Technology Facilities Council, and many others to develop and release AI models that impact the world not on some lengthy timeframe — but today.
Over the last year, we’ve seen a paradigm shift in the way AI has been deployed around the world, and it’s just part of the longer-term shift I believe is happening in how the world computes. As I said last year, I believe that advances in semiconductors, AI, quantum computing, systems, and hybrid cloud will converge into a computing platform that will be more powerful and secure than anything we’ve seen before. With the advent of powerful foundation models, the tools underlying modern hybrid cloud computing, and the new quantum systems coming online, I believe this vision is coming closer to a reality each year. When used collectively, these technologies will help solve some of the most pressing problems facing enterprise and society today.
Let’s look now at the major trends we see emerging across the areas of research that we focus on, and the work we did in 2023 to bring us closer to the vision I just outlined. For a complete list of all the research we carried out in 2023, you can visit our publications database. You can navigate the sections of the post at your preference through the table of contents below:
Foundation models will multiply the productivity and multi-modal capabilities of AI.
2023 was a massive year for the proliferation of AI in enterprises and IBM Research has been the engine of innovation behind many of the company’s largest releases.
In May of this year, IBM launched watsonx, our new enterprise AI and data platform. One of the key components is watsonx.ai, a studio for training, tuning, and deploying foundation models (such as large language models) at scale. We conceived, incubated, and matured the studio within IBM Research. Many of the foundation and fine-tuned models on watsonx have come directly from work within IBM Research. We have also been instrumental in the creation of the infrastructure that powers watsonx, the data sources available on the platform, and its new governance tool.
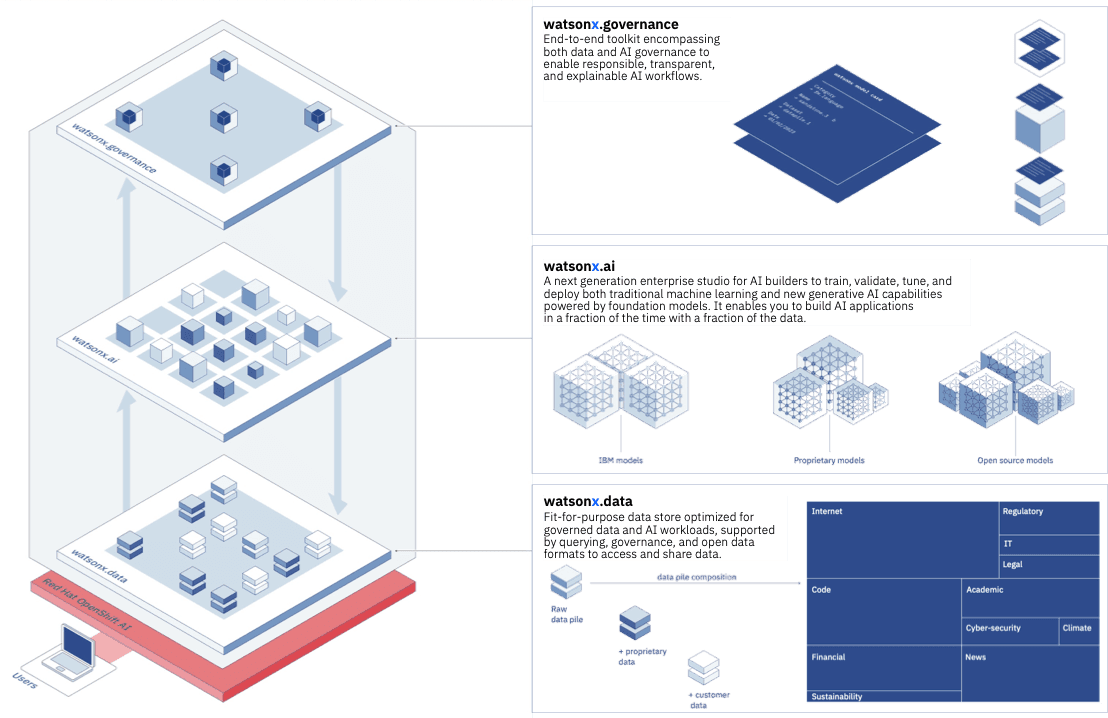
We’re making AI a powerful tool for every industry at the scale that enterprises require. For that, we focused our AI research in 2023 in several areas:
- watsonx.ai platform
- Foundation models
- Use cases
- Safety and governance
watsonx.ai platform
Open source
Because we believe that the future of AI relies on the open-source community, we’ve leveraged open-source technologies in the watsonx.ai platform. For example, given its plug-and-play nature and ability to easily add new hardware backends, PyTorch is a key component that we’re using to allow IBM’s clients to use watsonx in hybrid cloud environments with varying hardware backends. We have also made contributions to PyTorch — including distributed training, transformer block optimizations, and PyTorch Compile — that enable us to write distributed checkpoints to S3 compatible object storages (typically used in cloud native settings) for 30 billion parameter models 72 times faster than the existing centralized scheme, and our contributions to PyTorch Compile let you infer our watsonx models two to three times faster than an eager approach with no accelerated transformers. We will continue to contribute significantly to PyTorch beyond 2023, including auto-parallelization strategies for ease of distributed training, improving transformer blocks’ compute time, and adding support for enabling our new AIU chips as a backend in PyTorch.
OpenShift AI for training and validation on watsonx.ai
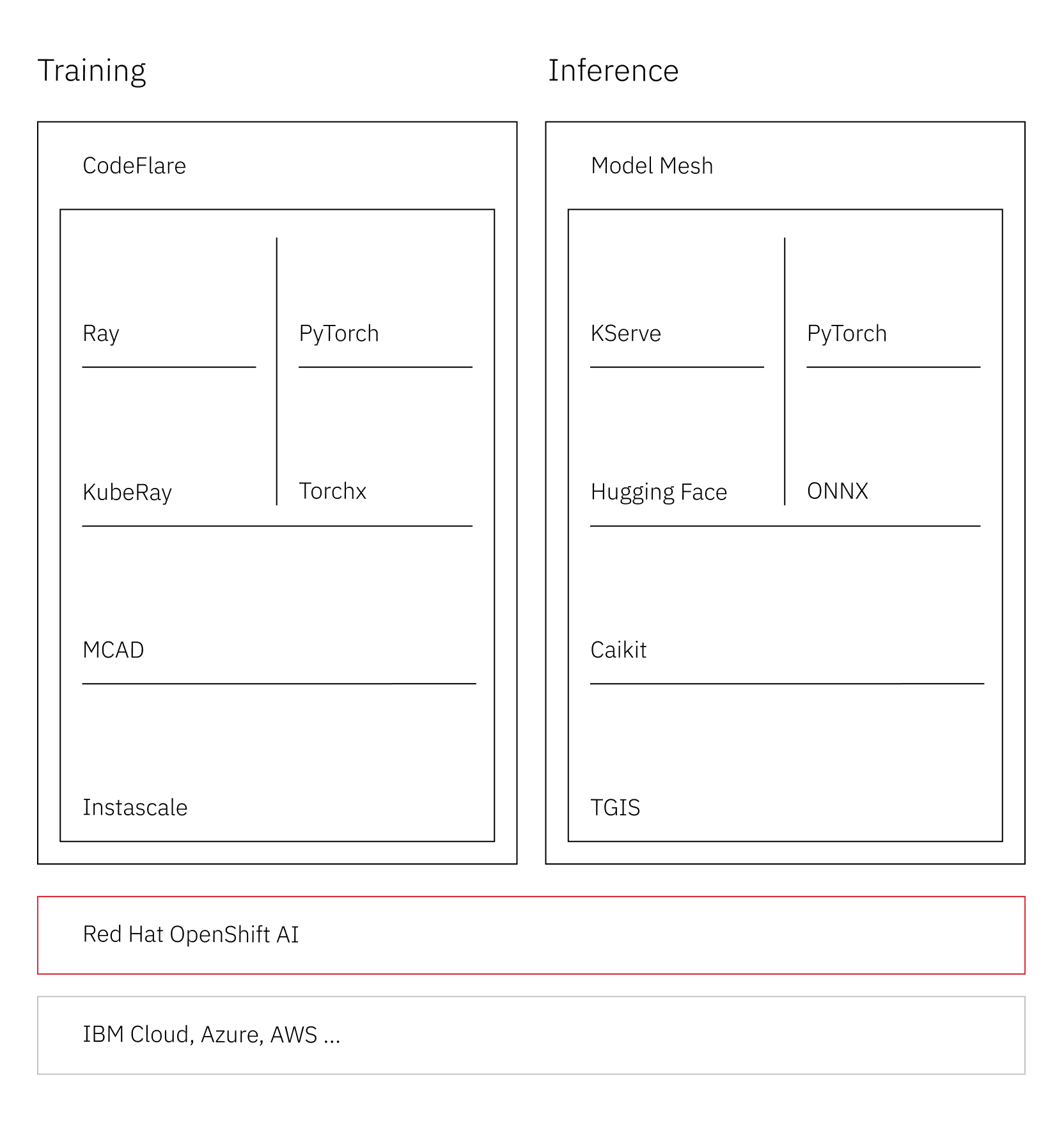
Importantly, we reimagined our full technology stack to accelerate how we train, fine-tune, and deploy foundation models. We built a high-performing, cloud-native AI training stack with Red Hat that was made available through OpenShift AI and forms the basis for the watsonx platform. It delivers the utility of traditional HPC systems with maximum hardware utilization and efficient use of high-performance infrastructure, thanks to new open-source components, like the CodeFlare SDK, Multi-cloud App Dispatcher (MCAD), and InstaScale, and the integration with Ray and PyTorch. This comes with the flexibility, portability, and productivity benefits that a hybrid cloud user experience provides. Today, the stack runs on the entire Vela cloud-native supercomputer, handling training jobs that require anything from single to more than 512 GPUs. We released the stack under Red Hat’s OpenShift AI Open Data Hub.
watsonx.ai inferencing
Working with the IBM Data and AI product team, we doubled the performance of model inferencing on A100 and V100 GPUs (two times lower latency or double the number of concurrent users, based on the situation) using a warmup time compilation strategy that allows different optimized models to be constructed during model loading times, while defaulting to eager, unoptimized execution when optimized artifacts do not match the request (such as batch size, or sequence length). This is the first of four suites of optimization that Research intends to introduce in watsonx.ai — compile, accelerated transformers, tensor parallel, and quantization — and has already been rolled out on three models in watsonx.ai. Our goal is to provide multiplicative speedups with each optimization.
Data engineering
Data engineering for training our models is another critical process for us, as large training corpora of high quality and quantity tokens has been shown to play a crucial role in producing high-performing large language models (LLMs). In 2023, we built and deployed seven releases of the multi-trillion tokens IBM data pile corpus.
Model evaluation
We talked about data preparation, training, and inferencing of our foundation models. We also need to validate and evaluate new LLMs coming out of IBM and existing LLMs from open-source and internal sources for use in IBM products like watsonx.ai. We created a foundation model evaluation framework for this, FM-eval. It’s designed to be flexible and allow for tasks, datasets, and metrics to be easily added. To support it, we developed Unitxt, an open-source python library that provides a consistent interface and methodology for defining datasets, the preprocessing to convert raw datasets to the input required by LLMs, and the metrics to evaluate the results.
The increasing versatility of LLMs has also given rise to a new class of benchmarks that comprehensively assess a broad range of capabilities. But those benchmarks have massive computational costs, extending to thousands of GPU hours per model. Therefore, we’re looking into efficient evaluations that intelligently reduce the computation requirements of LLM evaluation while maintaining good reliability.
Foundation models
There is no watsonx.ai platform without the foundation models that feed it. We have already developed a wide variety of models, from conversation to geospatial models to foundation models for code, IT automation, application modernization, foundation models for document understanding, asset management, visual inspection, IT security, finance and cybersecurity, foundation models for time-series data, even foundation models for chemistry and biology. We have a well-oiled data and model factory to produce models for watsonx to bring value in business and scientific discovery for our clients and partners. Here’s a summary of some of them.
Geospatial foundation model with NASA
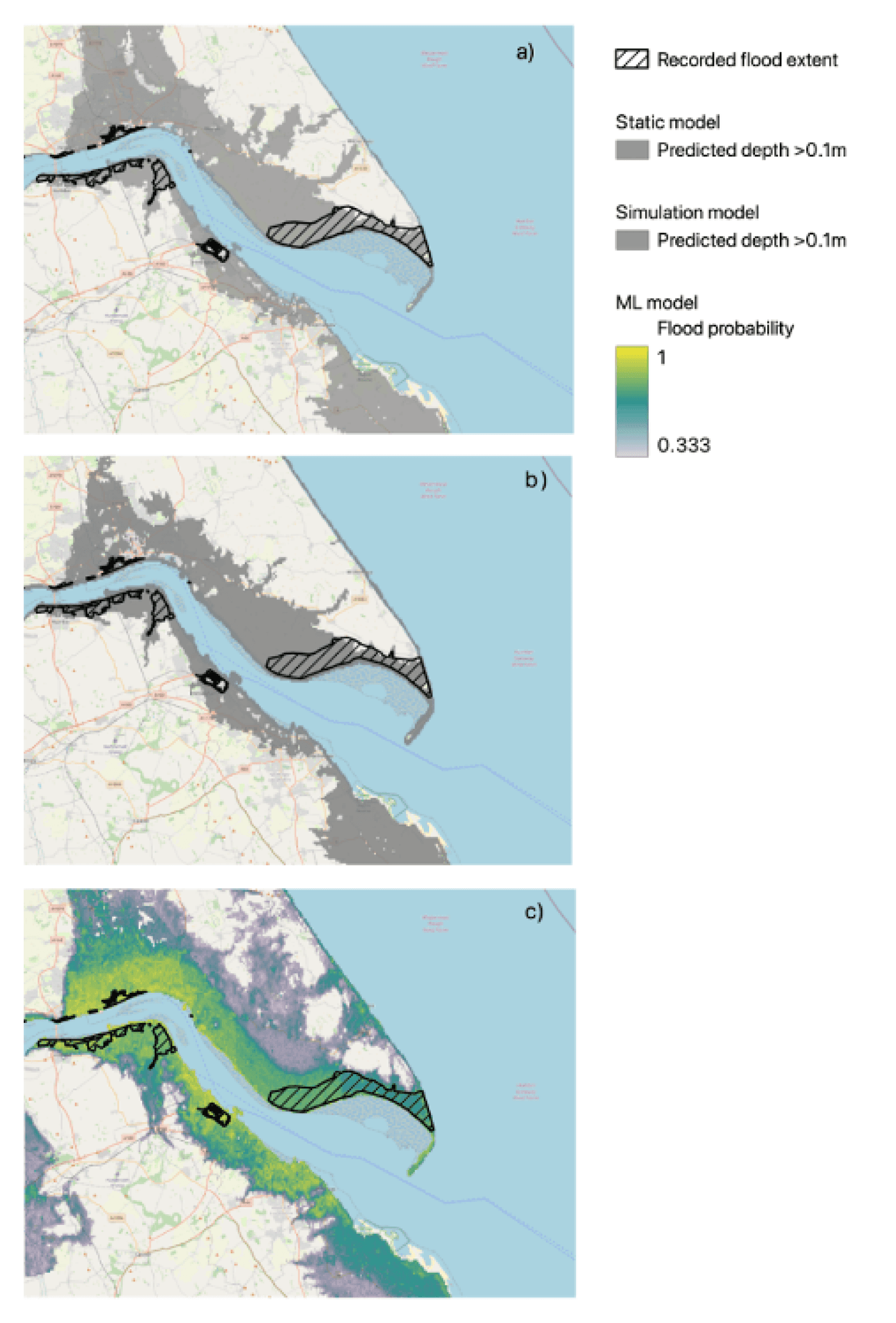
In collaboration with NASA, we released Prithvi, the first-ever foundation model entirely designed for geospatial data. Prithvi has shown a 15% gain in accuracy over state-of-the-art techniques with half the customary labeled data. Its ability to generalize across a spectrum of applications holds profound significance for both the scientific and business communities. It's already been trained to recognize things like the extent of historic floods and fire burn scars, as well as changes in land-use and forest biomass.
Using NASA’s satellite data, we provided examples from flood-related applications to illustrate how AI can leverage new geospatial datasets, improve the computational efficiency of models, and enable uncertainty quantification. By streamlining the process of translating weather and climate data into actionable information, AI can play a key role in building climate change resilience.
We’re now building a commercial version of the geospatial foundation model via watsonx and will scale up Prithvi globally with novel architectures and expanding our key strategic partnerships. We will be also releasing with NASA a new foundation model for climate this year, initially trained on the MERRA-2 dataset, a combination of high-quality observations and estimates of past weather over the last 40 years. We will add other data later — including observational data from fixed weather stations, floating weather balloons, and planet-orbiting satellites — into one multi-modal model.
Foundation models for code
In our AI for Code initiative, we’re using AI to enhance the capabilities of developers and reduce the ever-widening skills gap in the domains of application modernization and IT automation. We’re using purpose-built and trusted state-of-the-art foundation models, including IBM's granite.20b code model with its COBOL and Ansible variants. AI for Code is the foundation of IBM's latest watsonx Code Assistant (WCA) family of products that provide AI-generated, high-quality code recommendations based on natural-language requests or existing source code.
A couple years ago, we launched Project Wisdom for Red Hat Ansible in collaboration with Red Hat. Now as part of it, in new research in 2023, we had Ansible Lightspeed using large language models customized for code to automatically generate an Ansible playbook to build IT automations from a description in plain English. This research underlies WCA for Red Hat Ansible Lightspeed, an AI service released in October 2023 that streamlines Ansible code writing to help enterprises accelerate IT automation.
In a pilot with Citi, WCA for Red Hat Ansible Lightspeed has already led to 62% less time to create playbooks, 2X less critical failures, and an expected $80M+ savings in 3 years (conservative estimate). Furthermore, no developer required external support while using watsonx Code Assistant (i.e. documentation, Stack Overflow), as compared to 24X external outreach without WCA. Our AI for Code research is also powering IBM watsonx Code Assistant for Z, a new capability to help enterprises accelerate the transformation of their legacy applications, translate services from COBOL to Java, and save developers time and reduce human error. We will continue to introduce new modalities of WCA, such as WCA for Enterprise Java and a code assistant base to solve unique enterprise challenges by enabling companies to bring their own domain/languages, customize the state-of-the-art WCA code model, and deploy anywhere.
Foundation models for document understanding
To help automate business processes, we developed a multi-purpose foundation model for documents (FMD), IBM’s first multi-modal foundation model that can jointly process document images alongside the embedded text with state-of-the-art performance. FMD builds upon IBM Research-specific optical character recognition (OCR) models that accurately extract text from scanned documents, even when the scans are poor quality.
Foundation models for visual inspection
But it’s not just code, documents, and natural language — AI in computer vision is also experiencing a surge of innovation fueled by the advent of vision transformers (ViT) and the release of large segmentation models like Segment Anything (SAM). We’re extending this technology to technical inspection domains such as infrastructure, automotive, manufacturing lines, quality control, and many others where defects are often small and rare and need to be precisely detected in large, high-resolution images with a very small amount of ground truth data. We’re building visual inspection foundation models for IBM’s Maximo Visual Inspectionthat can be tuned for a specific inspection task using a minimal amount of fine-tuning data, or even by visual prompting using just a few images.
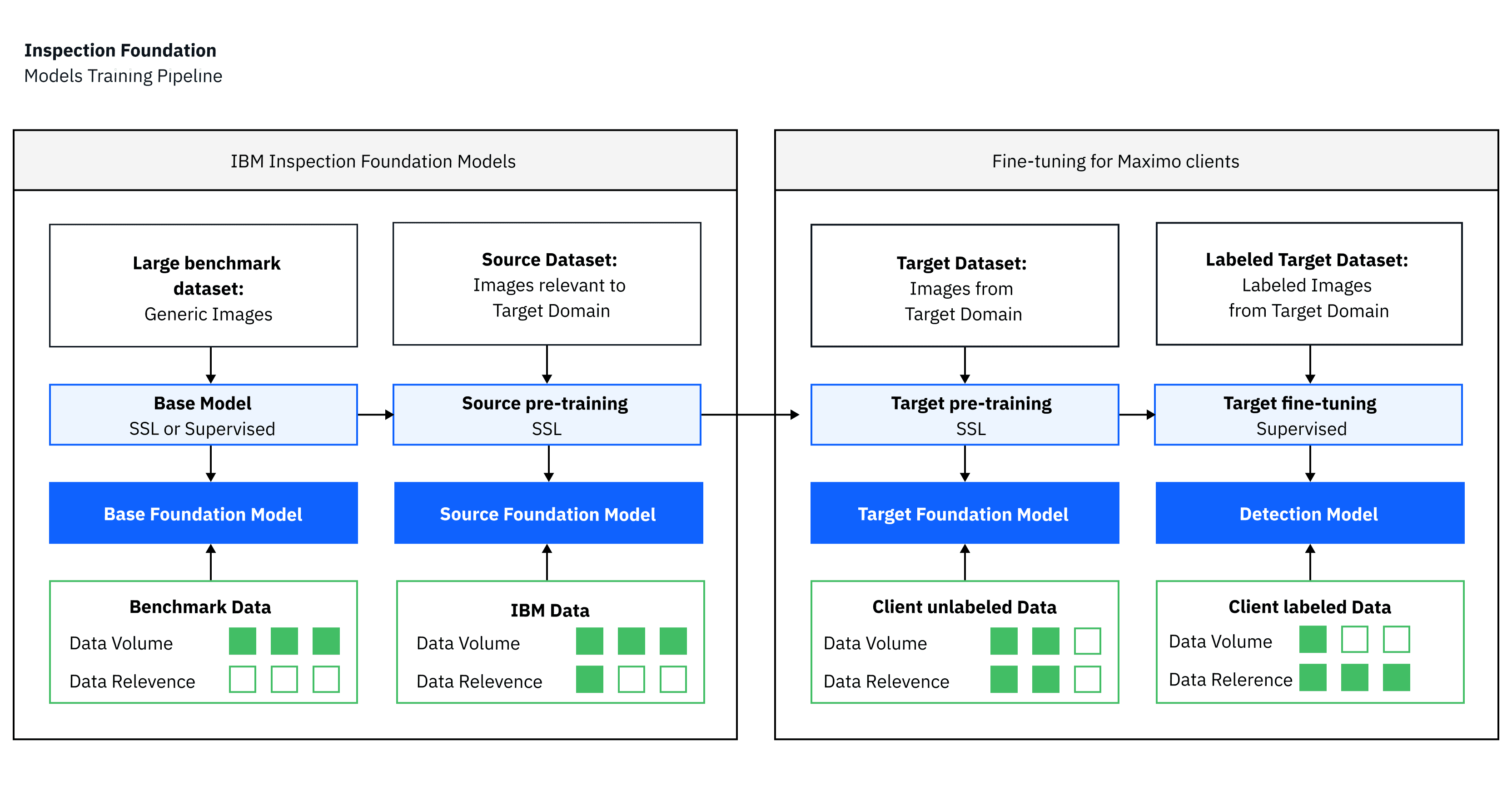
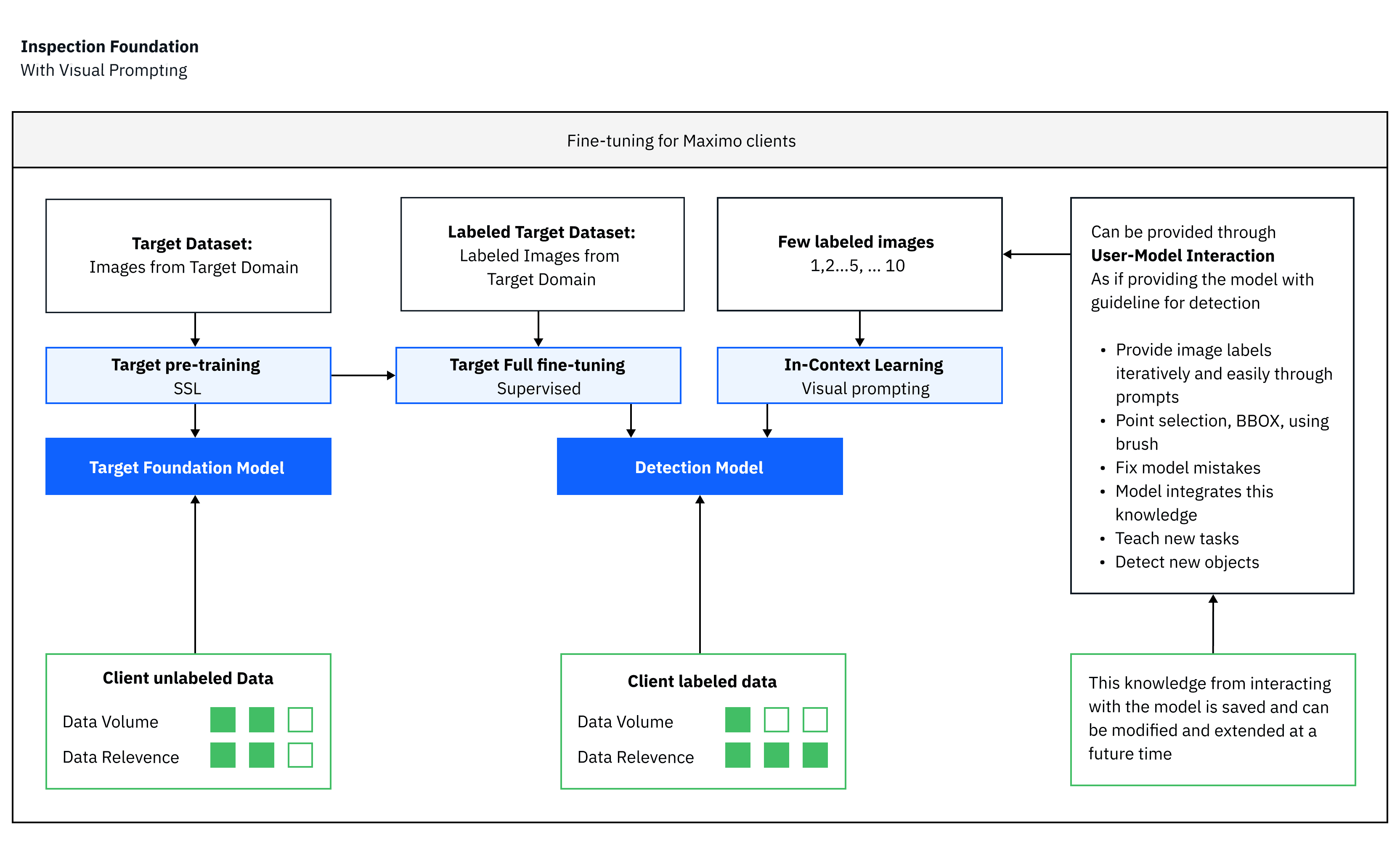
Extending IBM’s Maximo for Civil Infrastructure workflow, we also built a full cloud service that ingests inspection work-orders, enables clients to conveniently navigate, explore, manage, and review hundreds of thousands of images and defects, and produces fully digitalized inspection reports, including measures, assessment, and required repairs.
Foundation model for asset management
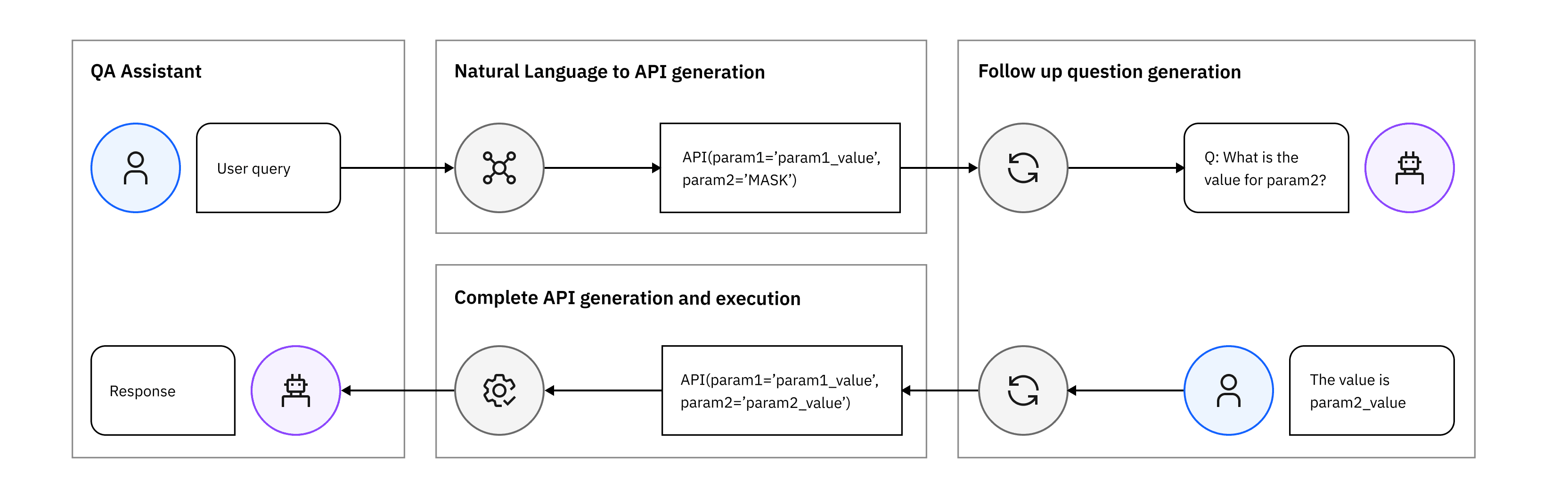
As automation increases in industrial applications, to empower experts to find answers to their domain-specific questions with AI, we developed a framework that offers a semantically rich representation of domain-specific data — documents, data lakes, process and instrumentation diagrams, or time series data. Our framework retrieves relevant context to the prompt to produce more relevant answers. We can also enable guard-railing by generating graph API calls that query and interact with the knowledge graph domain to teach the LLM to reason about the domain and invoke the right APIs. Using the APIs prevents hallucinations and is more cost-efficient in reflecting changes in systems that are evolving over time.
Foundation models for IT and security
We’re also developing foundation models to help enterprises be able to quickly understand, contextualize, triage, and respond to IT incidents. These AI models encompass multiple modalities: language to understand documentation, threat reports, analyst notes, and ticket data, code to understand configuration, policies, scripts and infrastructure as code, logs and events of activities running on systems, application traces and topology when available, and time-series data associated with metrics reporting on the health of systems. With these models, we’re in the process of infusing incredible analytics into IBM products to provide unprecedented threat intelligence and proactive incident resolution. But incident resolution is only part of IT, you also have IT infrastructure support. Working with IBM Infrastructure, we’re automating hardware infrastructure ticket resolution with LLM and retrieval-augmented generation (RAG) technologies to accelerate case resolution by 20% to 30%.
Foundation models for finance and cybersecurity
We developed new data construction methods to train models for specialized domains like finance and cybersecurity that outperform general-purpose models and open-source industry vertical models. You can find them in watsonx.ai as slate.125m.english.finance and slate.110m.english.cybersecurity.
Foundation models for time-series data
Back in 2020, IBM Research introduced time series transformers (TST), the first transformer architecture for self-supervised time-series and representation learning. We followed that in 2022 with PatchTST to address the limitations of DLinear. Now in 2023, we introduced PatchTSMixer, a lightweight MLP-Mixer alternative for time-series forecasting and representation learning with high computational efficiency and performance. We released both PatchTST and PatchTSMixer in Hugging Face to encourage innovation in the time series domain. These models provide HF compliant APIs for pre-training and fine-tuning, perform real-time inference, and support downstream applications like forecasting, classification, and regression.
Foundation models for chemistry and biology
From business, we move to scientific discovery. In the letter last year, I told you about our large chemical language model, MolFormer. We have now expanded to a full suite of molecular foundation models that accelerate the development and discovery of chemicals, materials, small-molecule therapeutics and biologics. These are our MoLFormers. We also launched a cloud-based service for MoLFormer inference.
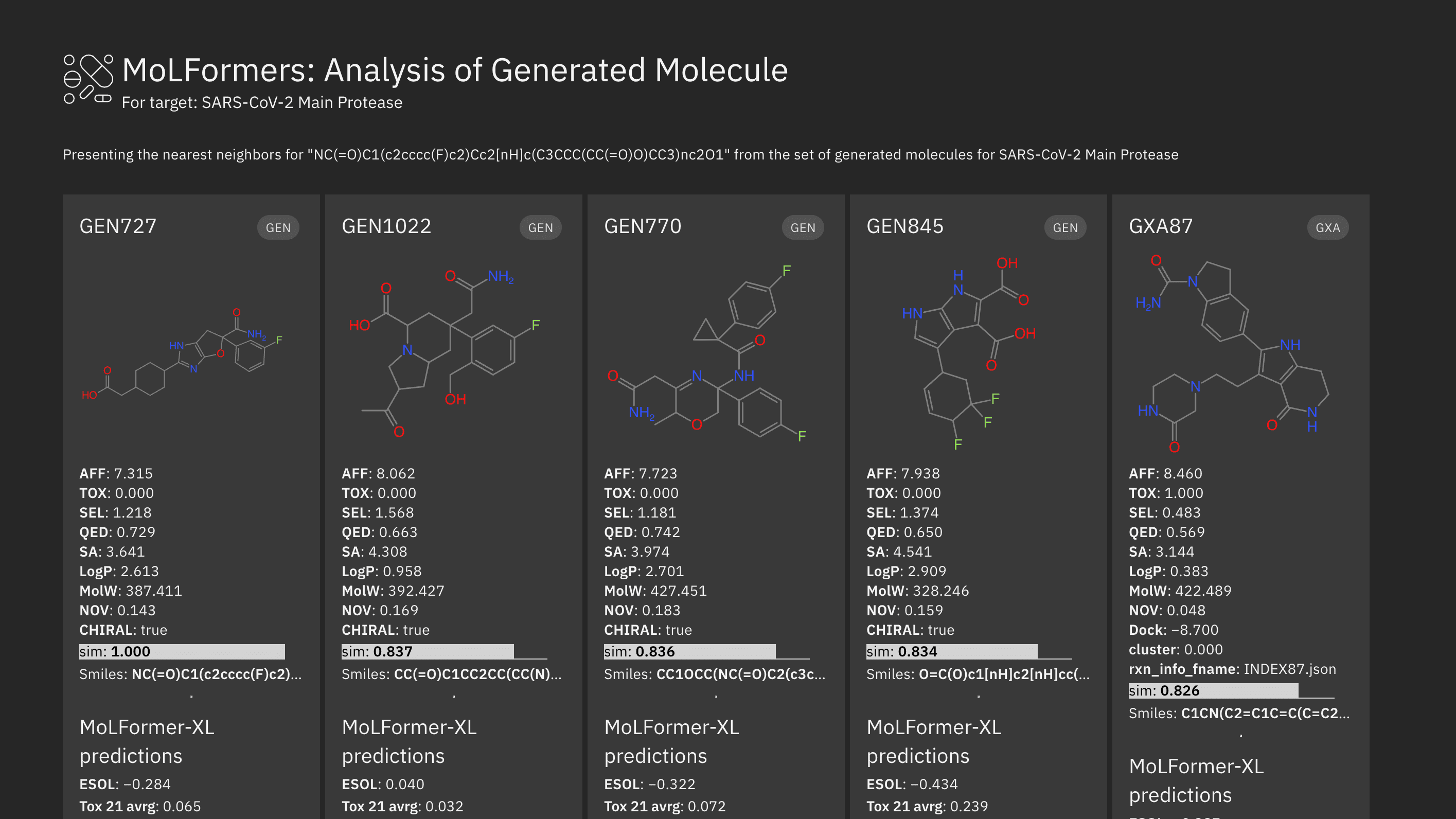
In the MoLFormers suite you can find, for example, MoLFormer-XL, a chemical language model trained on 1.1 billion molecules using a novel combination of rotary positional encodings and linear attention transformer. The model shows emergent behavior with molecular geometry learning that can provide GPT-like generative capabilities for molecular design applications. Our deep generative foundation model CogMol successfully accelerated the discovery of SARS-CoV-2 antivirals and broad-spectrum antimicrobials to four to six week and a 10-50% success rate, compared to two to four years and has a success rate of less than 1% for typical scientific research. For biologics, we introduced the predictive model GearNet, a geometry-aware protein encoder. Industry leaders such as Moderna and Cleveland Clinic are using these models for drug discovery and material design.
Efficient models for detecting hate, abuse, and profanity
Going beyond industry or science use cases, we built English and multilingual models to detect hate, abuse, and profanity (HAP) in data used for training AI models and deployed them on the pre-processing pipeline. The English HAP detector is available in watson NLP and used as a guardrail for generative AI models in watsonx.ai.
Distilled models for fast inference and fine-tuning
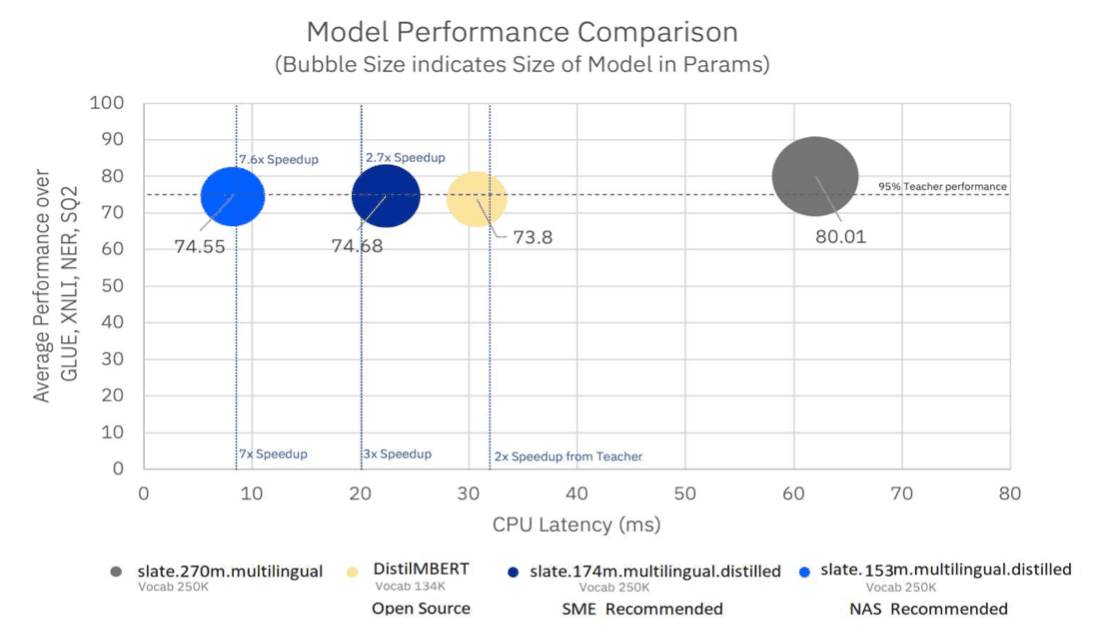
Of course, we don’t just build models, we optimize them for efficiency so they can be deployed in resource-constrained or time critical environments. We developed a multilingual knowledge distillation neural architecture search to find the optimal smaller student architecture for task agnostic distillation from a multilingual teacher model. We used it to distill the 12-layer slate.270m.multilingual model for watsonx.ai — which supports nearly 100 languages — into the four-layer slate.153m.multilingual.distilled. The distillation method that our neural architecture search recommended outperformed an earlier SME-recommended architecture by producing a model that is about 7x faster than the parent model within 95% of the parent model’s accuracy. We deployed slate.153m.multilingual.distilled in Watson NLP and products that use Watson NLP and watsonx.ai, Watson Studio, IBM Cloud Pak for Data (CPD), and Watson NLP for Embed.
Use cases
In 2023, we’ve also been busy putting our AI and data platform watsonx, and the foundation models we build for it, to work in proven, high-impact use cases. As a company, we chose to focus on digital labor, customer care, and application modernization. Let me highlight just a few of those use cases.
Conversational search
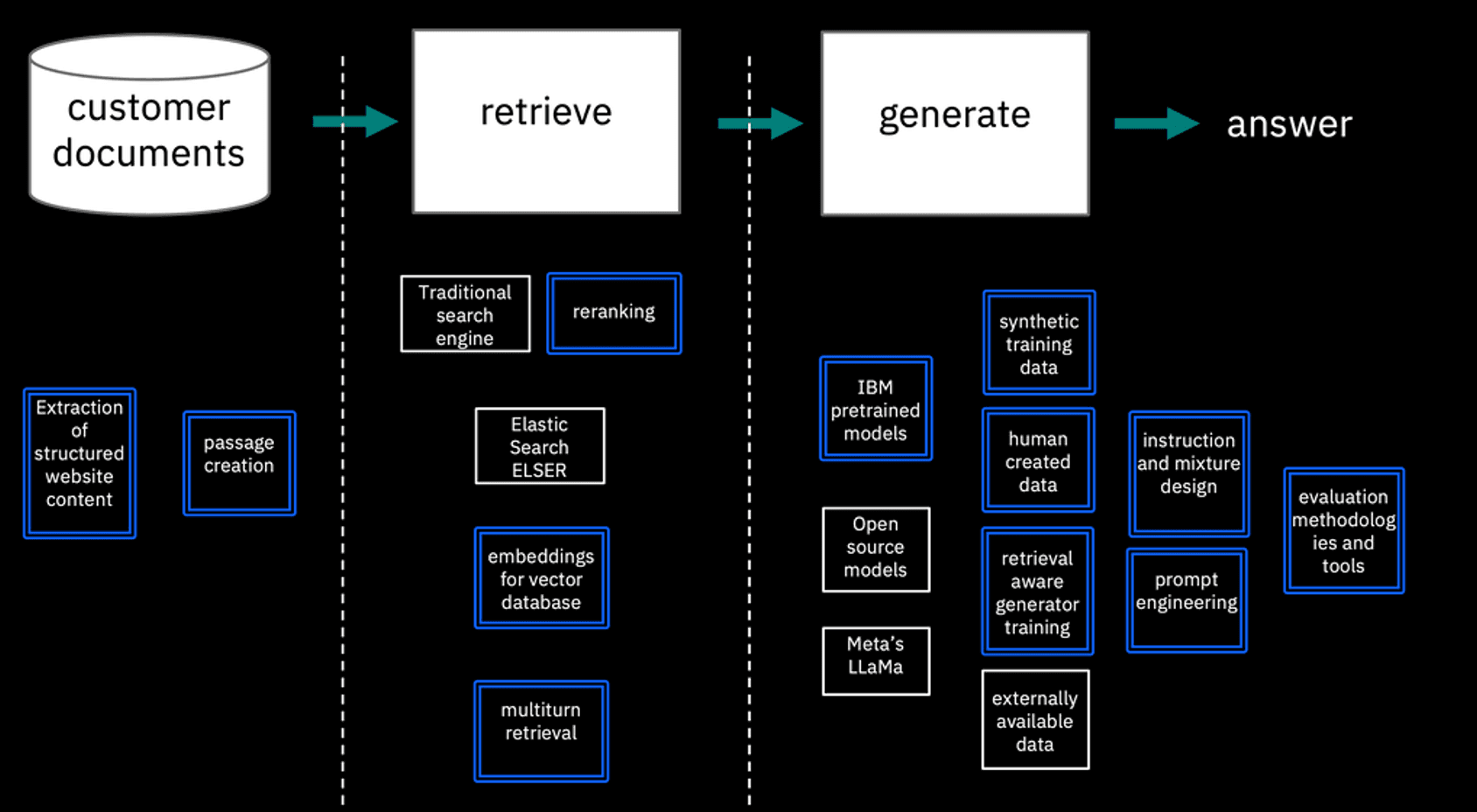
When a client asks questions about a given database of customer documents, “retrieve and generate” (RAG) methods are commonly used to answer the questions through generative methods.
At Research, we’re creating technologies to enhance the accuracy and user experience obtained from RAG solutions in watsonx and Watson Assistant (you should try the demo). IBM already has leading edge technology to process PDFs for RAG as part of Watson Discovery, now Research is developing technology for HTML processing based on IBM-trained models for reranking or native vector search. We’re generating embeddings for retrieval and reranking that can outperform existing alternatives where accuracy is the primary focus and investigating techniques for reranking and search. We’re also creating a robust generative model that can handle single and multiple turn conversations with end users.
Digital labor
In digital labor, we’re leveraging foundation models to automate and improve the productivity of knowledge workers by enabling self-service automation in a dynamic, effortless, fast, and reliable way — without technical barriers. For this, we focus on four key areas.
We’re generating and enriching Open API specifications from web URLs containing the API documentation and using low-code editing techniques to enable users to quickly customize the details. We’re using a code foundation model to provide the ability to express the intent of a complex automation in natural language, followed by a combination of foundation models and AI-planning to navigate and reduce the search space of skills and synthesize complex sequences of skills to satisfy the intent under the policies that need to be enforced.
To automate performing tasks or calling APIs, we built an LLM-based slot filling model that identifies information in a conversation and gathers all the information required for completing an action or calling an API (imagine, for example, the information you need to open a ticket) without much manual efforts. To save enterprises the cost and effort of host LLMs for each individual automation task involving APIs, we’re training a single LLM for multiple of these tasks with minimal drop in performance for each individual task. Early results point to API-integrated LLMs used for tasks such as API detection, slot filling, and sequencing tasks having equal or better performance than LLMs trained for the individual tasks.
Finally, we’re building no-code UI automations. Instead of having technical experts record and encode repetitive action flows for a knowledge worker to use them, we’re moving towards automations built and used through foundation model-powered conversational instructions and demonstrations by the knowledge worker, thereby enabling self-service automation. We treat these automations as skills, allowing them to be composed with any other skill available.
IT operations
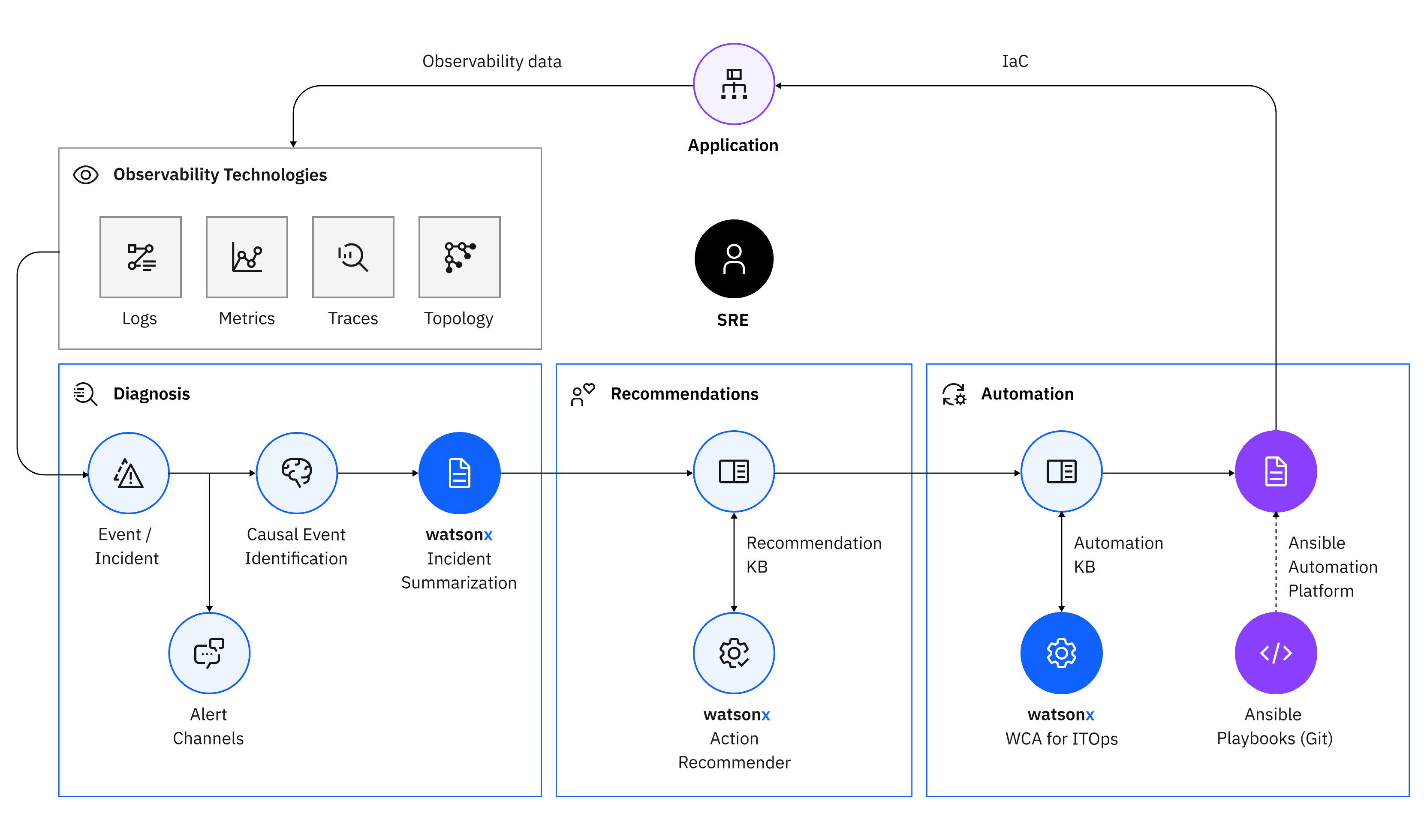
Another area that benefits immensely from foundation models and generative AI is the operation of modern IT in multi-cloud environments. Keeping systems up and running effectively in these environments requires proactive incident resolution. At IBM Research, we’re infusing foundation models and advanced AI in IBM ITOps offerings to transform ITOps from reactive to proactive, automating as much as possible the implementation of resolutions for upcoming IT issues before they turn into outages.
We developed novel foundation models to encode log data and represent temporal event sequences to make better predictions and risk forecasts for IT issues, including OpenShift OCP cluster upgrades for Red Hat. We also perfected an AI system for root cause identification using novel causal analysis and reinforcement learning, complemented with foundation model-based summarization techniques to ease the consumption of diagnosis results. We built an action recommendation module using foundation models within a retrieval-augmented generation pattern to automate the identification of key remediation actions to take given diagnosis summaries. Aspects of this module are live and showing strong improvements for IBM Software Support and Red Hat Support. To close the incident remediation loop, we’re using watsonx Code Assistant to translate action recommendations outputs into code that can be executed to resolve issues. This will be infused in several IBM offerings in 2024, starting with AIOps Insights and Instana.
Supporting indigenous languages
We believe that the positive impact of foundation models is not limited to business and science but can extend to societal and cultural issues. In fact, in 2023 we partnered with the Tenonde Porã indigenous community in Brazil to build writing-support tools based on fine-tuning LLMs in their native Guarani Mbya language. The partnership is part of a bigger project between IBM Research and the University of São Paulo to strengthen Brazilian indigenous languages using ethically-guided AI and natural language processing technologies that consider social and cultural contexts.
Safety and governance
Trust is the ultimate license to operate. The benefits of AI are moot if the end-users cannot have confidence in the predictions and content generated by the models. At IBM, we have a long-standing history of delivering trustworthy AI, putting safety and governance into the heart of the AI lifecycle.
Human-centered AI
We strive to ensure technological advances in generative AI and foundation models are developed and deployed in ways that augment human abilities, preserve human control, and align with our ethical values. To that end, in 2023 we developed novel user experiences for model selection and comparison in watsonx.ai, new methodologies for identifying and mitigating AI model risks in watsonx.governance, and a conversational graphical user interface for the watsonx.data semantic automation layer to provide effective visual and conversational interactions in the watsonx.data interface.
Our design principles for generative AI applications, a joint work between Research and Design, guide how to design and build effective interactions with intent-based generative AI systems. We have used them internally across IBM and with customers to educate and empower our design population to craft user experiences for generative AI applications that foster productive and safe use.
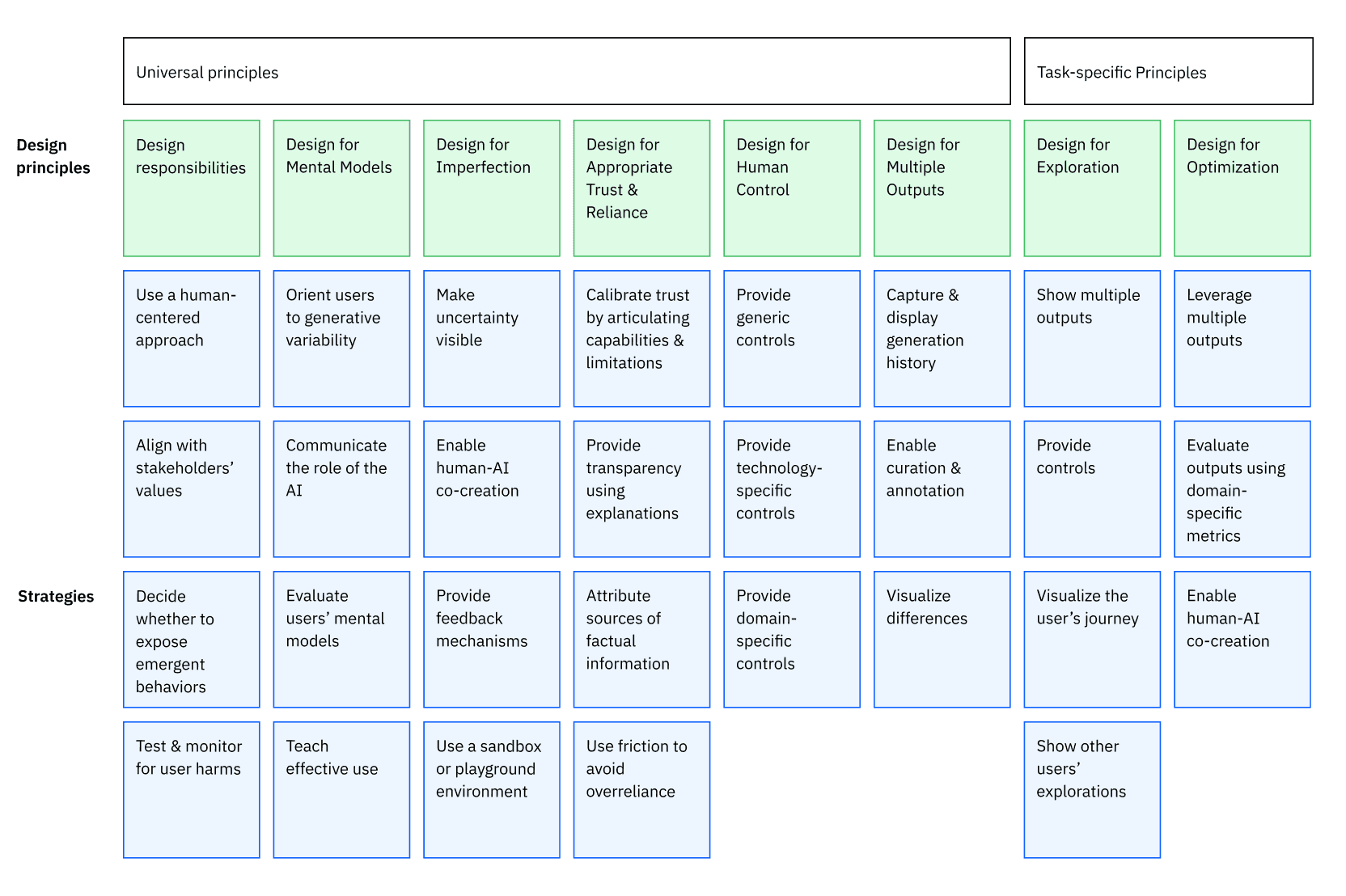
With Fairness 360, we developed and open-sourced powerful algorithms for bias mitigation in AI. We combined them with a human-centered approach for presenting and visualizing fairness metrics to demonstrate a potential of up to 42% more accurate decision-making about bias mitigation. As part of our work with partners in the AutoFair project, we are creating novel solutions that involve stakeholders in fairness decisions, make models more transparent, and mitigate bias to address the need for trusted AI and user-in-the-loop tools and systems in a range of industry applications. We are also adapting existing bias mitigation toolkits to empower users to understand the implications of their algorithmic choices and align with their needs.
Principled and responsible AI
In keeping with our focus in trustworthy AI, in 2023 we advanced solutions for problems such as robustness, uncertainty quantification, explainability, data drift, privacy and concept drift in AI models. We developed practitioner-friendly bias mitigation approaches, proposed methods for understanding differences between AI models in an interpretable manner, studied the maintenance of AI models from the robustness perspective, and created methods for understanding the activation space of neural networks for various trustworthy AI tasks. We have analyzed adversarial vulnerabilities in AI models and proposed training approaches to mitigate such vulnerabilities. We made significant updates to our AI explainability 360 toolkit to support time series and industrial use cases, and developed application specific frameworks for trustworthy AI. We are invested in developing better datasets, pipelines, and tools for auditing AI models. Our scientists have also studied thornyproblemsin AI ethics calling for a productive discourse between different AI communities and new ways of approaching participatory engagements in existing and emerging technologies. In 2024, we will be able to learn, audit, and reflect on the decisions of foundation models in a principle-driven way. We will make significant strides in securing and guard-railing foundation models, thus making them more trustworthy.
Launching the AI Alliance
On December 5, we joined Meta and more than 50 partners in launching the AI Alliance, a partnership among leading industry, startup, university, and research organizations. In the alliance, we’re all collaborating to build, support, and advance open technologies and open innovation in AI, as well as safety and governance. We want to unlock proprietary bottlenecks in the AI ecosystem, especially in hardware and models. IBM Research will commit more than 300 people per year across multiple alliance projects, and over the next five years, we will commit over $100 million in external sponsored research funding and 100 million GPU hours of compute. Specifically, we will be focused on four major areas. We will work to build the Kubernetes ecosystem for AI workloads, and Ray and PyTorch for distributed, optimized training, tuning, and inference. We will build open-source models in multi-modal and scientific application areas. We will develop tooling and evaluation standards for safety, security, and trust. We will produce tools to enable generative AI applications for enterprise developers.

The future of computing is quantum centric.
Continuing with our mission to bring useful quantum computing to the world and make the world quantum safe, we have advanced hardware, theory, and software to usher in what we’re calling the era of quantum utility. We published results with the University of California at Berkeley demonstrating that, for the first time, quantum computers could run circuits beyond the reach of brute-force classical simulations. Since then, our clients and users have been running demonstrations in our 127-qubit systems to investigate the utility of quantum computing in their work domains. Our machines are no longer small systems only suitable to validate the principles of quantum computers. We are now in a regime where our quantum computers are powerful tools for advancing R&D in different domains.
In the 2022 annual letter, I shared with you our vision to build a modular computing architecture integrating quantum processors, classical computing resources, quantum communication networks, and classical communication networks between quantum processors working together with traditional high-performance computing. That is the definition of a quantum-centric supercomputer and in 2023, we made important advances toward it with new hardware, software, and significant results in error correction, algorithms, and more. All while we continue to grow our network of quantum innovation centers, government, research, and industry partners, and open-source developers to lay the groundwork for the future quantum computing ecosystem.
IBM and Berkeley demonstrate quantum utility
Last June, the cover of Nature featured our work with UC Berkeley, where we showed evidence that hardware performance improvements with error-mitigation techniques like zero noise extrapolation with probabilistic error amplification enable us to extract useful information from the output of quantum circuits with over 100 qubits and more than 2,000 operations.
In that work, we simulated the dynamical behavior of a two-dimensional transverse-field Ising model using all 127 qubits of our Eagle processor, while the UC Berkeley team used tensor networks and matrix product states in the Lawrence Berkeley National Lab’s National Energy Research Scientific Computing Center (NERSC)’s Cori supercomputer.

The result spurred a wave of interest, with clients and users running utility-scale demonstrations in our quantum systems that include simulating long spin chains, investigating quantum many-body dynamics, observing a phase transition from randomness to long-range Ising order, preparing the vacuum state of the lattice Schwinger model — a model of quantum electrodynamics in one spatial dimension + time, and generating efficient long-range entanglement and performing CNOT gate teleportation. We have seen a disruptive change in the scale and pace of problems that the quantum computing industry and community are running on hardware and one that was fundamental to bring useful quantum computing to the world. Today, we are focused on delivering utility-scale hardware co-designed with scalable software and developing applications using deep circuits with hundreds of qubits.
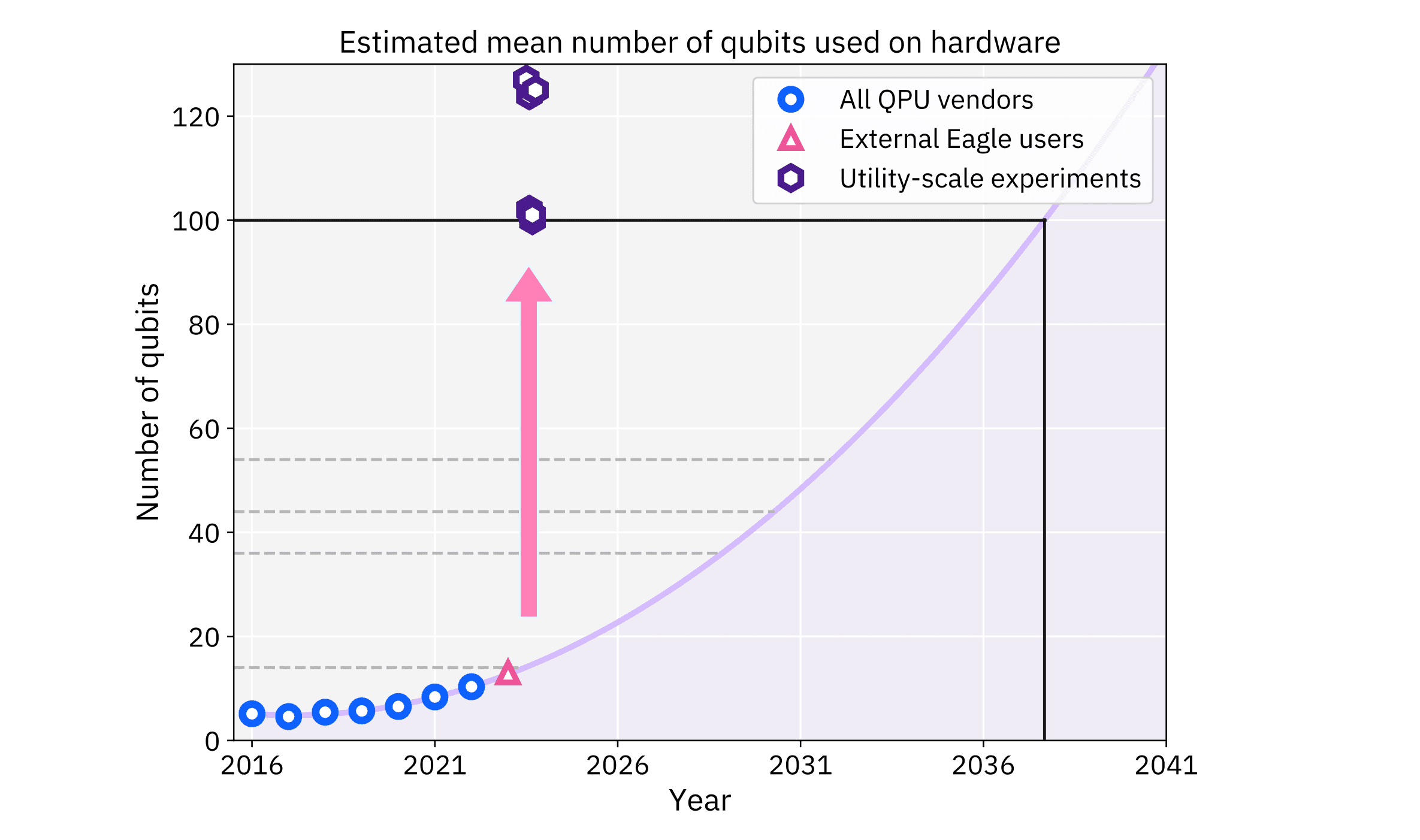
New quantum processors
Running utility-scale quantum circuits to solve larger problems requires pushing the scale and quality of quantum processors and in 2023, we did just that with Condor and Heron. At 1,121 qubits, Condor is the world’s largest quantum processor, pushing the limits of how many qubits can be fit on a single chip while yielding day in and day out. In it, we integrated and scaled all the innovations introduced in our previous processors without compromising performance. But utility experiments need more than scale, quality is paramount. To push quality, we completely redesigned our processor and gates with Heron, a 133-qubit chip with tunable couplers. It virtually eliminates crosstalk, has half the error rate of our best Eagle with some gate fidelities in the 99.9% range, and significant improvements in gate time. When used with error mitigation, it shows a 3x to 6x improvement over Eagle, with larger improvements when running deeper quantum circuits.

IBM Quantum System Two
A new era of utility calls for a new system. Last December, we unveiled the IBM Quantum System Two. It’s fully modular and flexible enough to grow with us as we continue to march forward in our journey. It’s initially housing three Heron processors with classical communication among them to enable parallelization of quantum circuits. But it will eventually accommodate processors with thousands of qubits — our Flamingo processor — capable of running over a dozen thousand of quantum gates in a single circuit. IBM Quantum System Two will serve as a building block of quantum-centric supercomputing. In fact, in May, we announced our plans to build a quantum-centric supercomputer with 100,000 qubits by 2033. This system will be able to run a billion gates on 2,000 qubits.

Utility-scale software
Exploiting the utility of quantum computers also demands software focused on performance, stability, and reliability. To that end, we built the first stable release of Qiskit with improvements in circuit construction, compilation times, and memory consumption. It is now Qiskit 1.0 and will be available in February 2024. We want to speed up the seamless execution of quantum workloads. To that end, we introduced Qiskit Patterns, a programming template supporting the four basic steps involved in running a quantum workload to simplify building quantum algorithms and applications at scale.
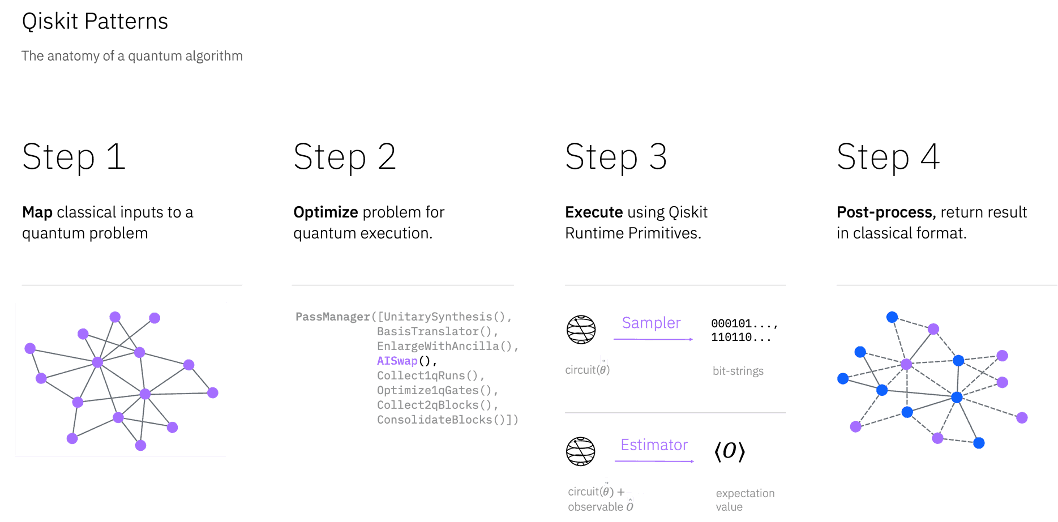
With Qiskit Patterns, we’re deploying Quantum Serverless as beta for the managed, unattended execution of patterns at scale. We’re also introducing a batch mode that allows you to submit multiple non-iterative queries at once and exploit parallelism or threading to run workloads up to 5 times faster.
Slashing the number of qubits needed for error correction
The next major advance in 2023 was the introduction of our new error correcting code. Our theorists found a new family of low-density parity check codes that need 10x fewer physical qubits to achieve the same level of error correction as the leading code — the surface code — with comparable gate fidelities required for its implementation. We call our code, one in the family, the Gross code. Implementing the Gross code requires innovations in qubit coupling that we’re already working on, but importantly, this new family of codes is giving us confidence that error correction is possible without requiring an unreasonably large quantum computer and is closer than we thought.
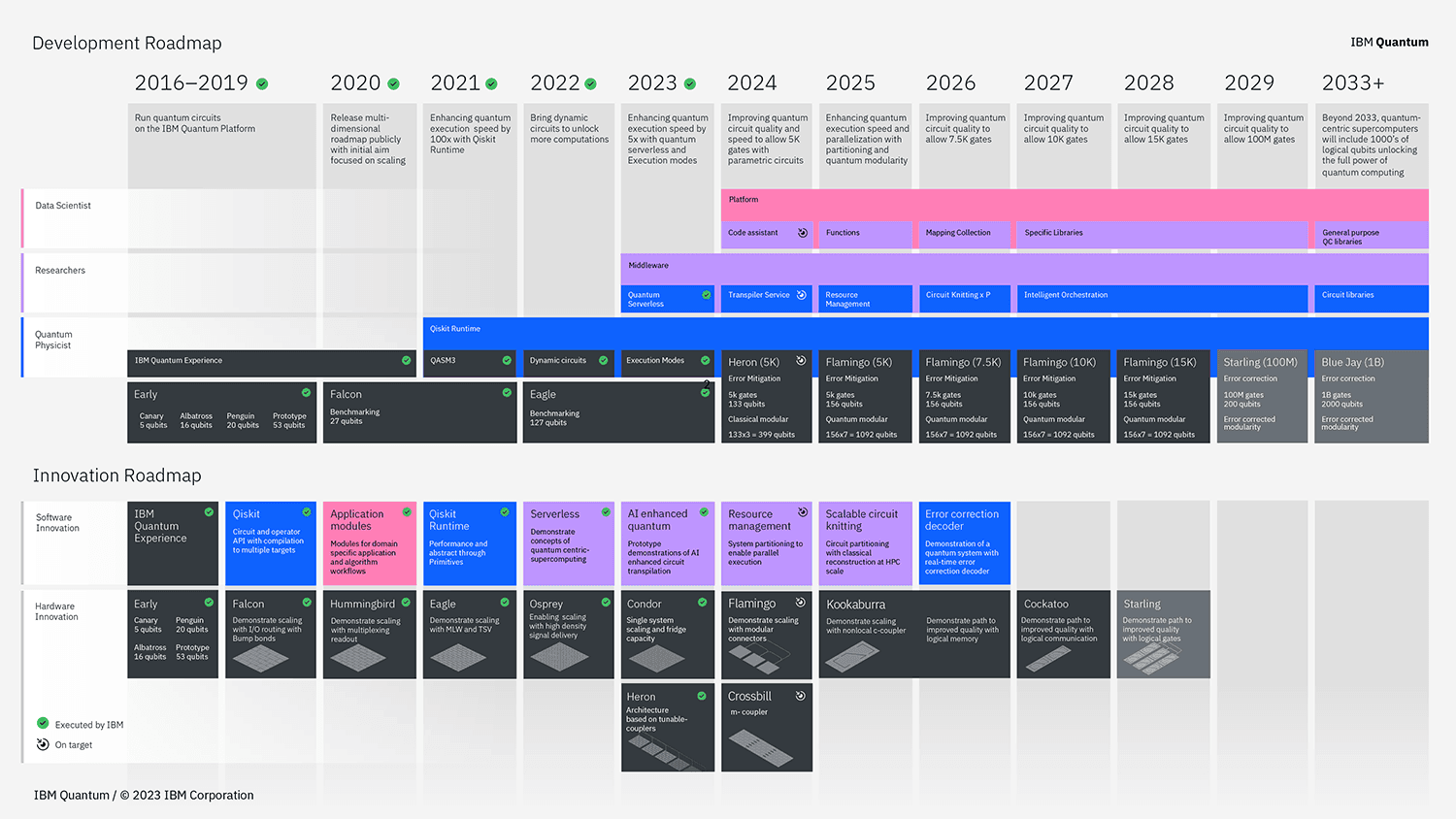
Our updated roadmap
All these major advances that I’ve highlighted guide and provide greater definition to our path. Hence, it was time to expand our roadmap. Our development roadmap defines the path for client-facing systems and services, stating the number of gates that the processors will be able to run in a single circuit. Our innovation roadmap charts the key demonstrations needed to go from utility to error corrected systems at scale. We will incorporate the innovations from this roadmap into the systems in the development roadmap, leading us to a system capable of running 100 million gates by 2029, and a system capable of running a billion gates by 2033.
Multi-region quantum computing
Quantum data centers need a new software integration layer. In 2023, we announced our multi-channel scheduler to meet that need. It’s a software layer sitting between the end-user, cloud services, and quantum data centers to facilitate access to multi-region computing using the Qiskit Runtime primitives to run quantum programs. It allows users to incorporate quantum resources from different regions depending on their needs or constraints, such as data sovereignty.
AI for quantum computing
At the end of the day, quantum computers are only as powerful as our ability to use them with simplicity. That’s why we’re bringing the power of generative AI for code through watsonx to make our quantum systems even easier to use by automating the development of code for Qiskit. We built this by fine tuning our granite.20b.code model — part of IBM’s Granite family of foundation models. It allows you to use natural language prompts to generate Qiskit code.
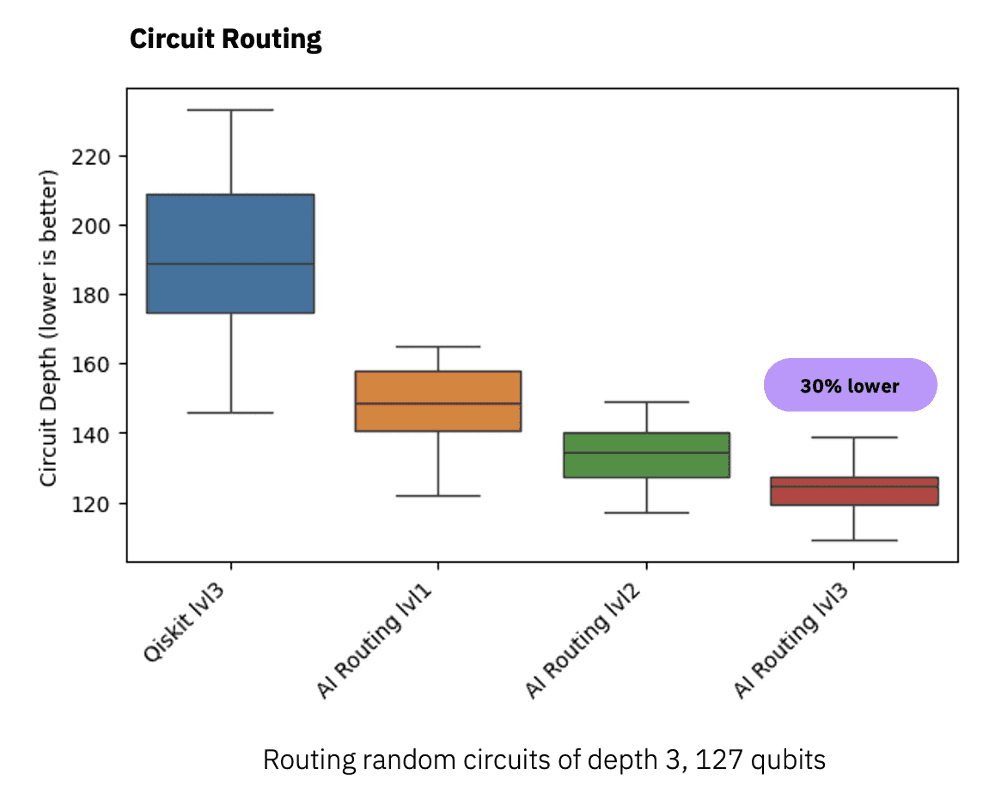
We also built a quantum circuit compilation service using reinforcement learning. The new AI transpiler passes produce optimized quantum circuits with 20% to 50% higher depth and CNOT count compared to equivalent Qiskit transpiler passes.
IBM Quantum Safe
To make the world quantum safe, we have been busy building quantum-safe technology. We released IBM Quantum Safe Explorer, a tool that scans code to look for cryptographically relevant artifacts, catalogs them, and produces a cryptography bill of materials (CBOM). This will be followed by IBM Quantum Safe Advisor to prioritize at-risk assets and data flows, and IBM Quantum Safe Remediator to test remediation patterns and work with different quantum-safe algorithms, certificates, and key management services.
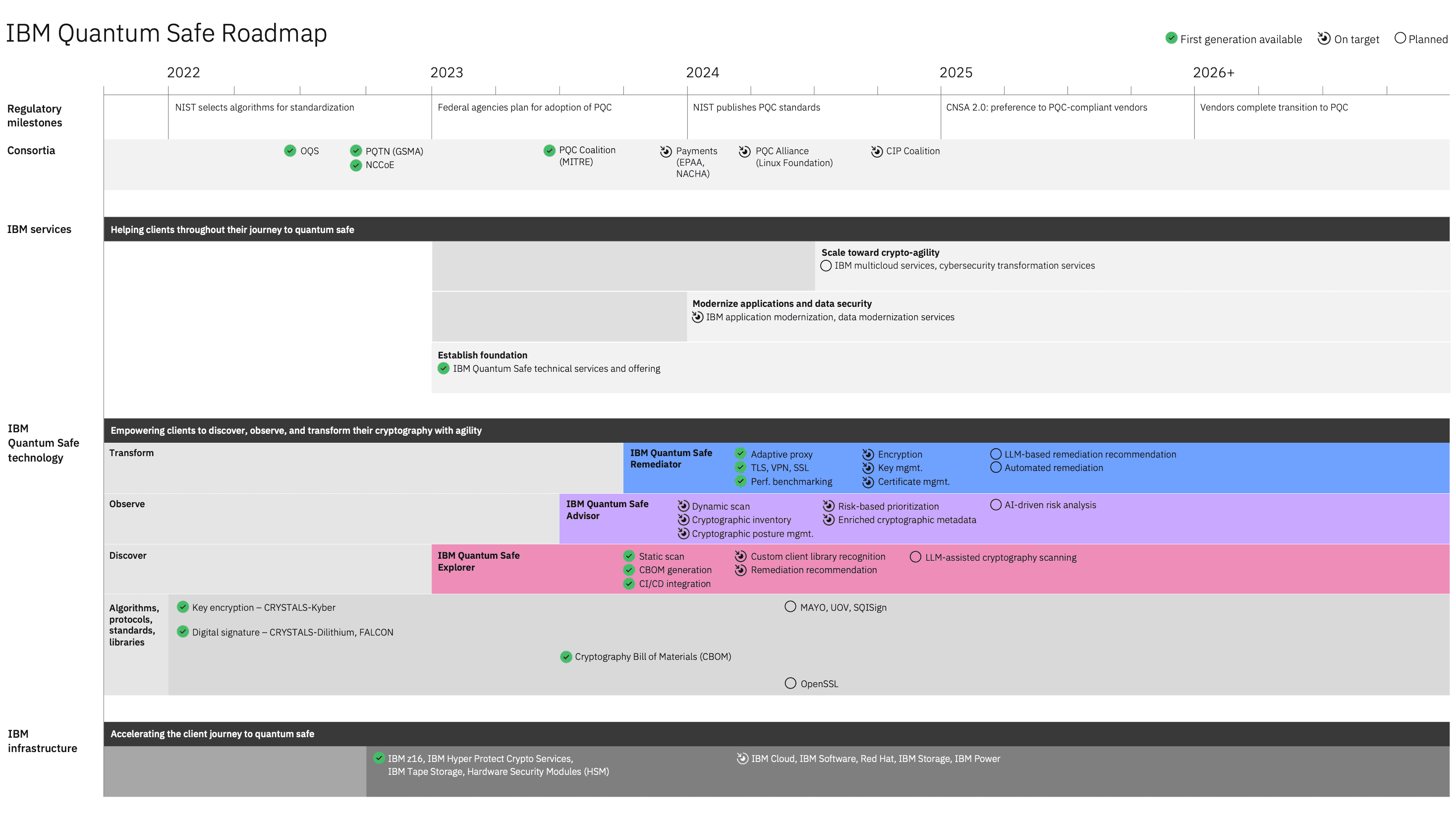
To give clarity on how we’re developing and bringing to market this technology, we updated our IBM Quantum Safe roadmap, where we outline how we will continue to advance quantum-safe cryptography research, foster industry partnerships, and develop a comprehensive set of tools and capabilities.
Nanosheets and chiplets are the transistor and semiconductor technology of the next decade.
Semiconductors are the backbone of the modern digital world and at IBM, we’ve been innovating in semiconductor technology and pushing the exponential growth of classical computing power for over half a century. Today, at the Albany NanoTech Complex and our global labs, we continue to improve semiconductor performance and make this technology more scalable and efficient with innovations like our AIU cluster, new chiplet structures and packaging processes, and updates to IBM Z.
Logic technology
After introducing the nanosheet in 2017, which has replaced the FinFET as the next generation transistor technology, we’re now improving the inner space formation and channel formation modules to enable gate-all-around nanosheet architectures leading to robust, higher performant devices for future technology nodes. We introduced a logic standard cell architecture to optimize the VTFET, with key design technology co-optimization scaling knobs that improve area scaling for better power-performance-area tradeoff.
In process technology, we made advances to wafer printing with sub-resolution assist features sizes below 8 nm to resolve a large range of pitches from 28 nm and below. We optimized the processes for spin-on metal oxide resists, including evaluating new coater/developer hardware and new resist development techniques to improve photo speed, defectivity, and critical dimension uniformity without degrading roughness in the metal oxide resist. We also addressed the fact that building a chip involves different generations of lithography equipment, with the newest generations printing on the lowest level and finest pitch features and older generations printing the larger features. Hence, we improved Monte Carlo simulations to quantify the overlay performance impact of combining a high-NA EUV exposure with a 0.33 NA EUV full field exposure and the benefit of overlay correction sets. This informs design layout placement to avoid hot spots.
To improve CMOS contact resistance as feature sizes shrink, we developed a contact cavity shaping process that leverages a reactive-ion etching and contact low-temperature epitaxy. That allowed us to reach a record low transistor contact resistance and 19% effective current device performance improvement. We used Synopsys’s Technology Computer-Aided Design to develop a new workflow that enables more accurate, complete, and faster technology evaluation at 3 nm and beyond than traditional process design kit (PDK)-based workflows. But to keep innovating logic technology, we need to rethink our methodologies to assess performance and so, in 2023, we investigated pre- and post-PDK methodologies to benchmark the performance of power delivery network designs in advanced technology nodes.
Heterogeneous integration and chiplets
Chiplets are the semiconductor technology of the next decade. It’s how we will meet the increasing demands for computing power, most recently driven by AI. That also requires innovations in heterogeneous integration and importantly, metrology for heterogeneous integration. Specifically, we need higher yield for through-silicon vias (TSVs) and bonded solutions. To help us get there, we developed a comprehensive picture of the stress evolution within arrays of TSVs using in-line Raman spectroscopy. Separately, in investigating overlay performance in permanent bonded wafer integration, we established direct relationships between incoming wafer distortion, bonder-induced distortion, and post-bond lithography overlay to a pre-bond level, which will help guide hardware design to address distortion challenges.
We know that silicon handle technology has multiple benefits for advanced chiplet applications. Therefore, we developed the next generation infrared laser debonding technology to release silicon handlers from 300 mm wafers of advanced CMOS nodes. It supports chiplet test vehicle build and integration and will help us with precision chiplet technology applications. Meanwhile, we have 3D integration with hybrid bonding, which has the potential to perform close to system-on-a-chip (SOC) at lower cost. We’ve been pushing hybrid bonding technology too, and in 2023, we developed a die-to-die and die-to-wafer copper/interlayer dielectric hybrid bonding methodology with the potential to increase the data throughput between chiplets, and the number of chiplets that could be installed in a given space. That would give us a system that would act more like a single SOC.

Our advances in direct bonded heterogeneous integration packages pave the way for this technology to be used for chiplet packaging, allowing us to optimize package size and reduce fabrication costs. To address the challenge of successfully bonding large silicon chips onto an organic package substrate with fine-pitch solder bumps, we came up with a new solder deposition approach that locally varies the resist thickness and resist opening diameter to increase the range of solder volume deposited on individual pads. We used the approach to heterogeneously integrate three different types of chips — a field-programmable gate array with over 188,000 pads at 40 μm pitch, high bandwidth memory, and an IBM AI chip — on an organic interposer substrate using copper-pillar micro-bump solder joints.
We provided a framework for modeling and joint simulation of signal and power integrity of die-to-die interconnects with advanced packaging technology, built a numerical simulation model to characterize the thermal performance of a 3D stacked heterogeneous integration package, and created a framework to perform an end-to-end calculation of the temperature distribution and resultant residual stresses obtained after bond and assembly of a 3D die stack.
In terms of applications of heterogenous integration, we presented a scalable heterogeneous antenna-in-package (AiP) module for a 24 to 30 GHz 256-element 5G phased array antenna. We showed that silicon interposer and organic substrates to package mmWave-scale active internet-of-things integrated circuits can lead to antenna modules with good performance, and demonstrated an FPGA-driven time-delay photonic reservoir computer.
AI for smart manufacturing
Heterogeneously integrated chiplets at the package level face the challenge of low assembly yield due to high package warpage. We used an AI-driven methodology to reduce how much asymmetric substrates warp. It can reduce the warpage by 70%. In addition, we used machine learning to optimize laser dicing process parameters to maximize dicing quality for a given substrate. We believe that our methodology extends to any complex, multi-factor-dependent separation process to find the optimized process window.
Neuro-inspired architectures
Semiconductors also hold the key to hardware that optimizes the AI lifecycle. In the case of the AIU, the chip was designed from the ground up for high performance and power-efficiency, high utilization, and maximum throughput in AI training. It is about simplification and reduced precision. We’re also working on new computing architectures to accelerate AI workloads by eliminating the von Neumann bottleneck.

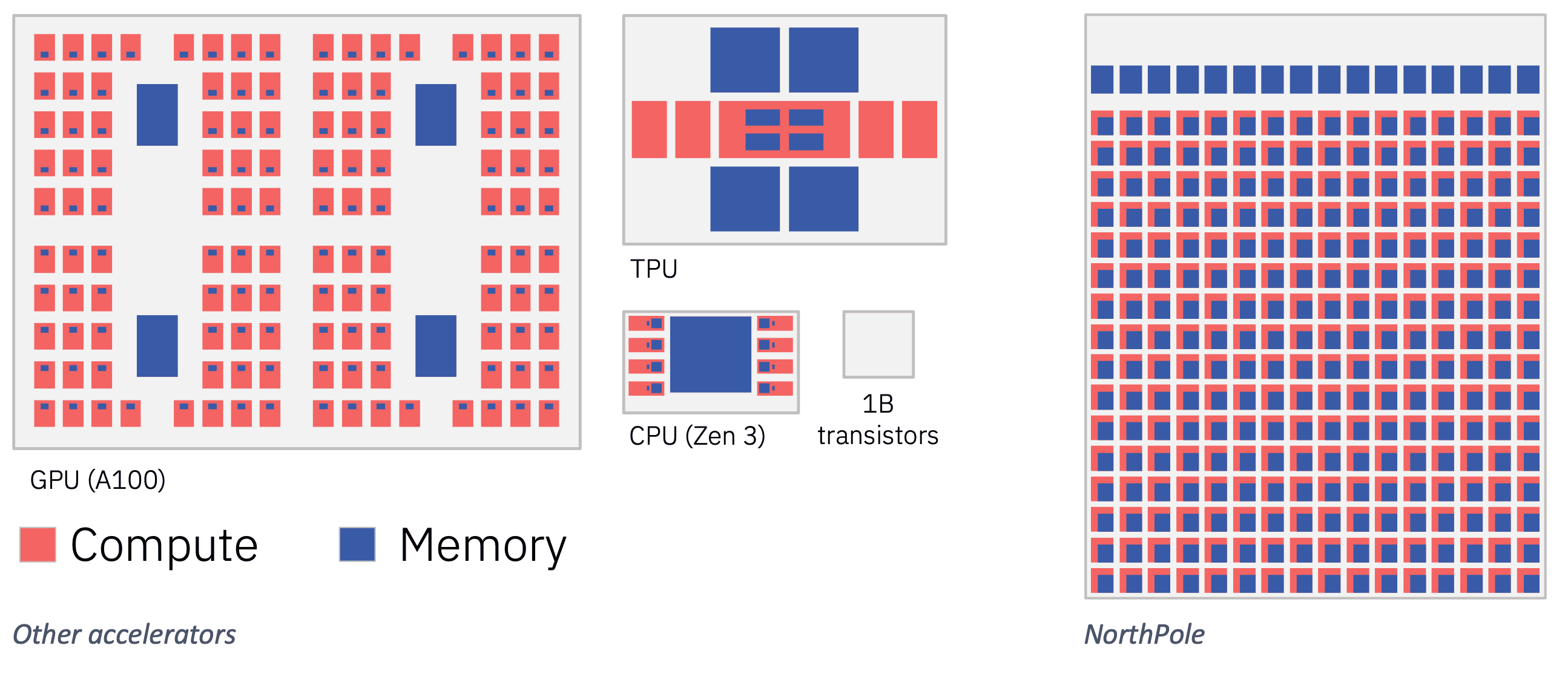
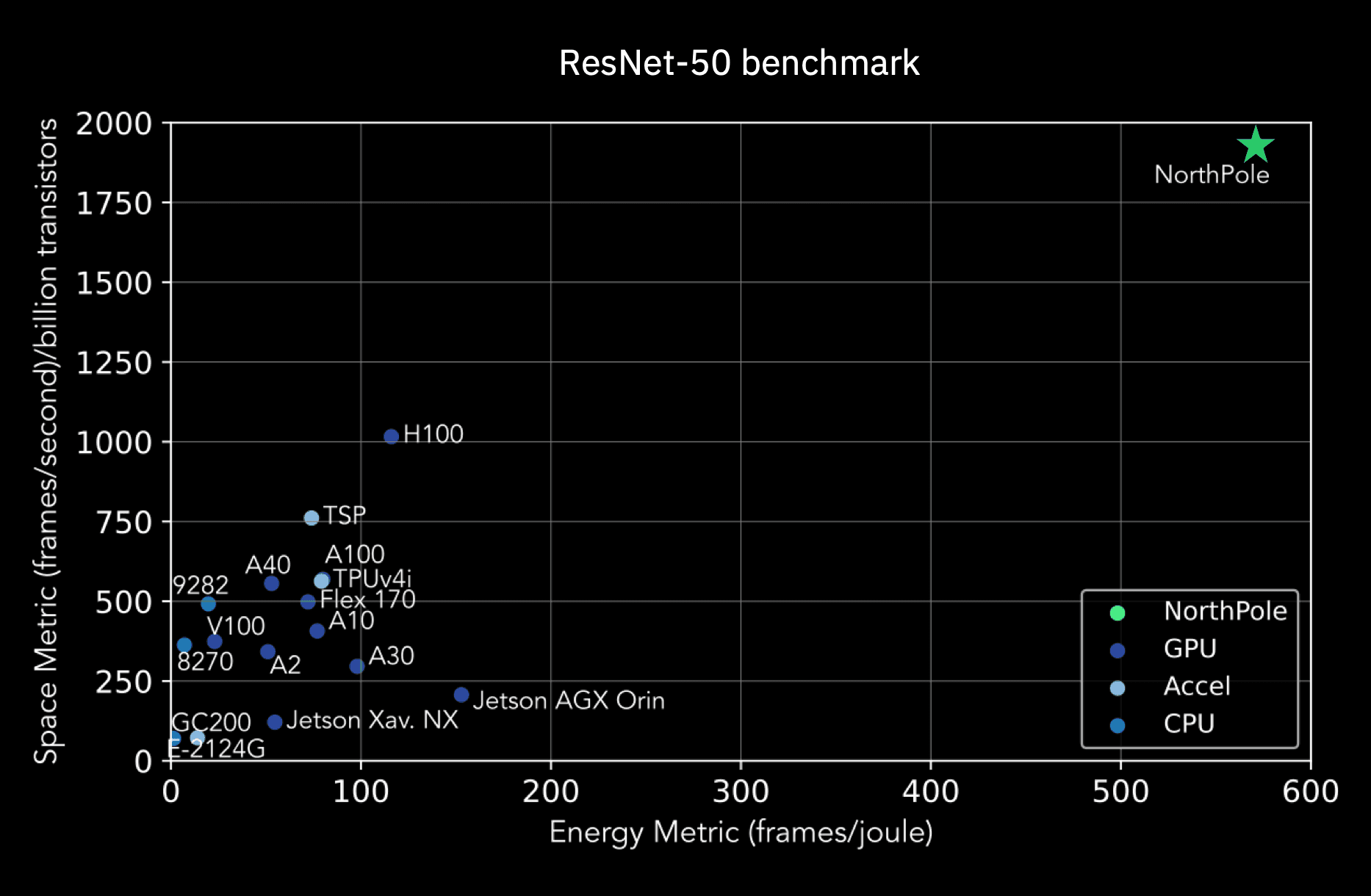
One such chip is NorthPole, featured in October Science. It’s a neural inference architecture that intertwines compute with memory on-chip and appears externally as an active memory chip. NorthPole is a low-precision, massively parallel, densely interconnected, energy-efficient computing architecture with a co-optimized, high-utilization programming model. On the ResNet-50 benchmark, relative to a GPU that uses a comparable 12-nanometer technology process, NorthPole achieves 25 times more frames per second (FPS) per watt, five times more FPS per transistor, and 22 times lower latency.
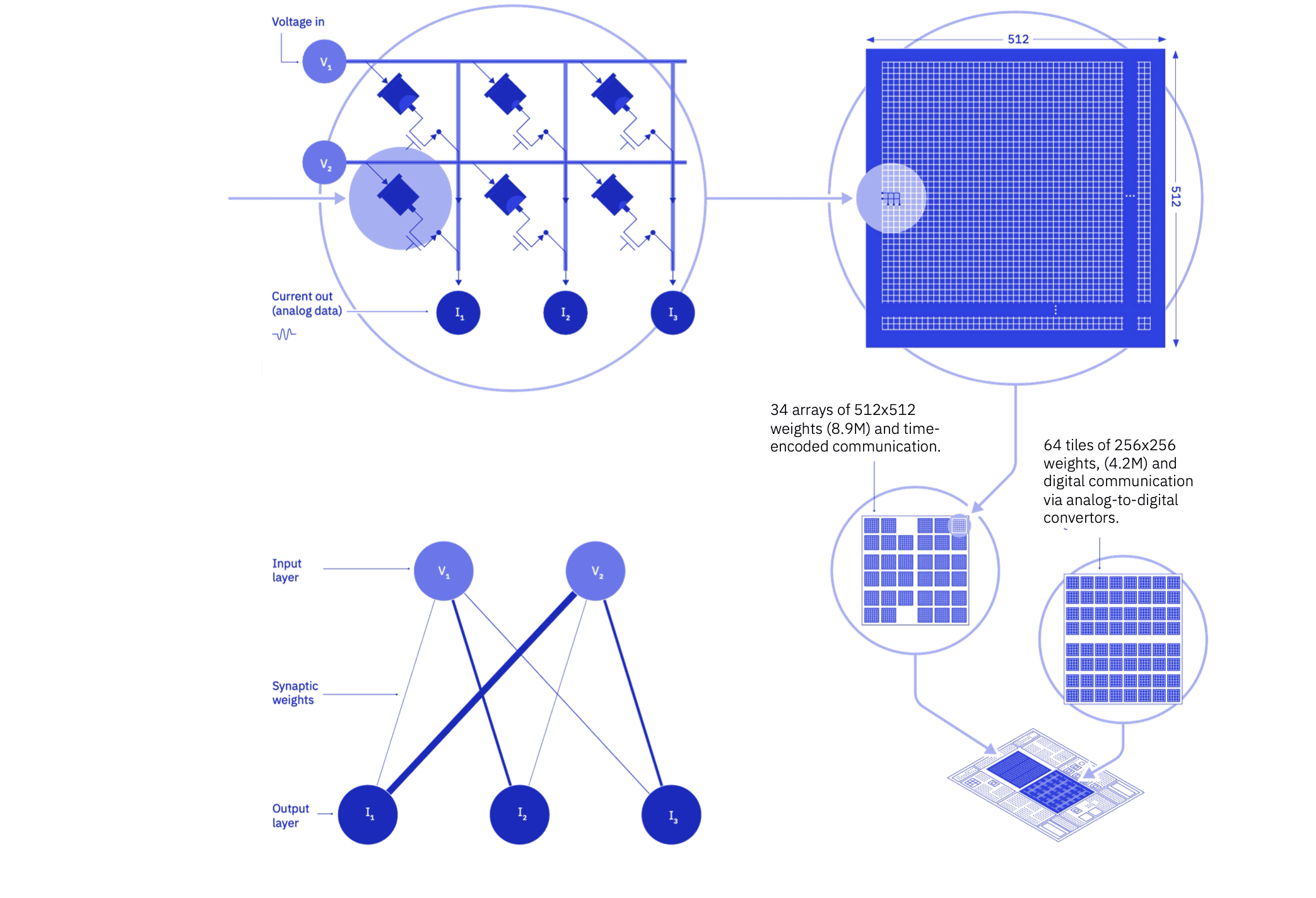
Analog AI
AI models with billions of parameters are extraordinary in their performance across a range of tasks but they’re also power-hungry beasts and conventional GPUs and CPUs are not energy-efficient enough for them. At the IBM Research AI Hardware Center, we’ve been working on analog AI since 2019 to improve the energy efficiency of AI hardware. It works by reading the rows of an array (or the “tile”) of resistive non-volatile memory (NVM) devices, and then collecting currents along the columns to perform the multiply-accumulate (MAC) operations that dominate deep learning within the memory device. We described an innovative architectural vision for an analog AI inference accelerator. The accelerator combines many tiles for MAC compute with a mix of special-purpose digital compute cores for any other tasks, connected with a massively parallel two-dimensional mesh. This would give us 40 to 140 times improvement in energy-efficiency over today’s hardware.
We also found that we could reliably improve the robustness of deep learning models to the noise and imperfections introduced by the analog devices and circuits by using a set of hardware-aware training techniques. We combined this with neural architecture search methods to design new convolutional neural networks optimized for accuracy on analog AI hardware while constraining the network size. This work won the best paper award at IEEE Edge 2023*.* The companion open-source project received the IEEE Open-Source Science award at the 2023 IEEE Services Congress.

But nothing beats actual implementation on real silicon, so we did it. We built an analog AI chip with 35 million phase-change memory devices across 34 tiles. We used it to implement a small keyword-spotting task and a large speech transcription task. Since this chip contained no on-chip digital-compute, this was not an end-to-end demo. However, so little additional compute was involved that, had it been implemented on the chip, the resulting energy efficiency (6.94 TOPS/W) would still be 14 times higher than best-in-class current products. Then in a paper featured in the cover of Nature Electronics, we built a 64-tile chip where each tile contained compact and low-power ADCs to digitize all MAC results. We used it to demonstrate several image-processing and caption-labeling tasks. In this case we performed all compute operations on-chip by using a combination of local and global compute blocks, with data motion between blocks assisted by off-chip data transport.
We have now demonstrated many of the building blocks needed to realize our architectural vision for a fast, low-power analog AI inference accelerator. With our hardware-aware training, neural architecture search, and tile-characterization techniques, we expect these accelerators to deliver software-equivalent neural network accuracies across a wide variety of models.
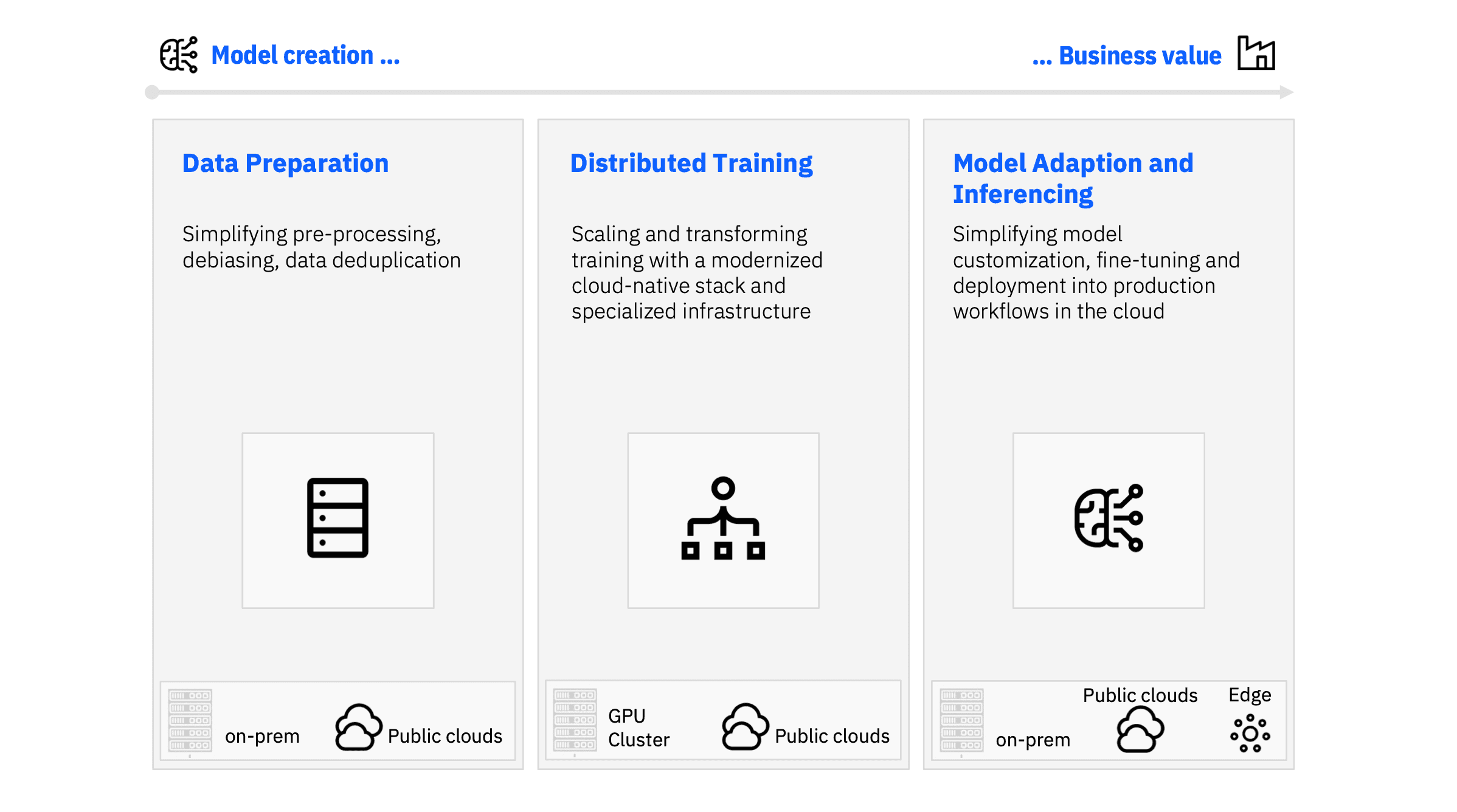
Multi-cloud computing will enable seamless deployment of enterprise AI at scale.
Our vision for computing involves an interconnected and composable computing fabric that allows applications to be built by seamlessly composing and integrating infrastructure, tools, and services from multiple clouds. That is our multi-cloud. It is a computing fabric that delivers that composability with simplicity, security, and sustainability. Importantly, it needs to ensure consistency of the platform and core services across all deployment locations. That is the vision that we’re working to realize. But already today, we’ve made great strides to simplify the development and deployment of production-level foundation models at scale in a multi-cloud environment.
Multi-cloud platform
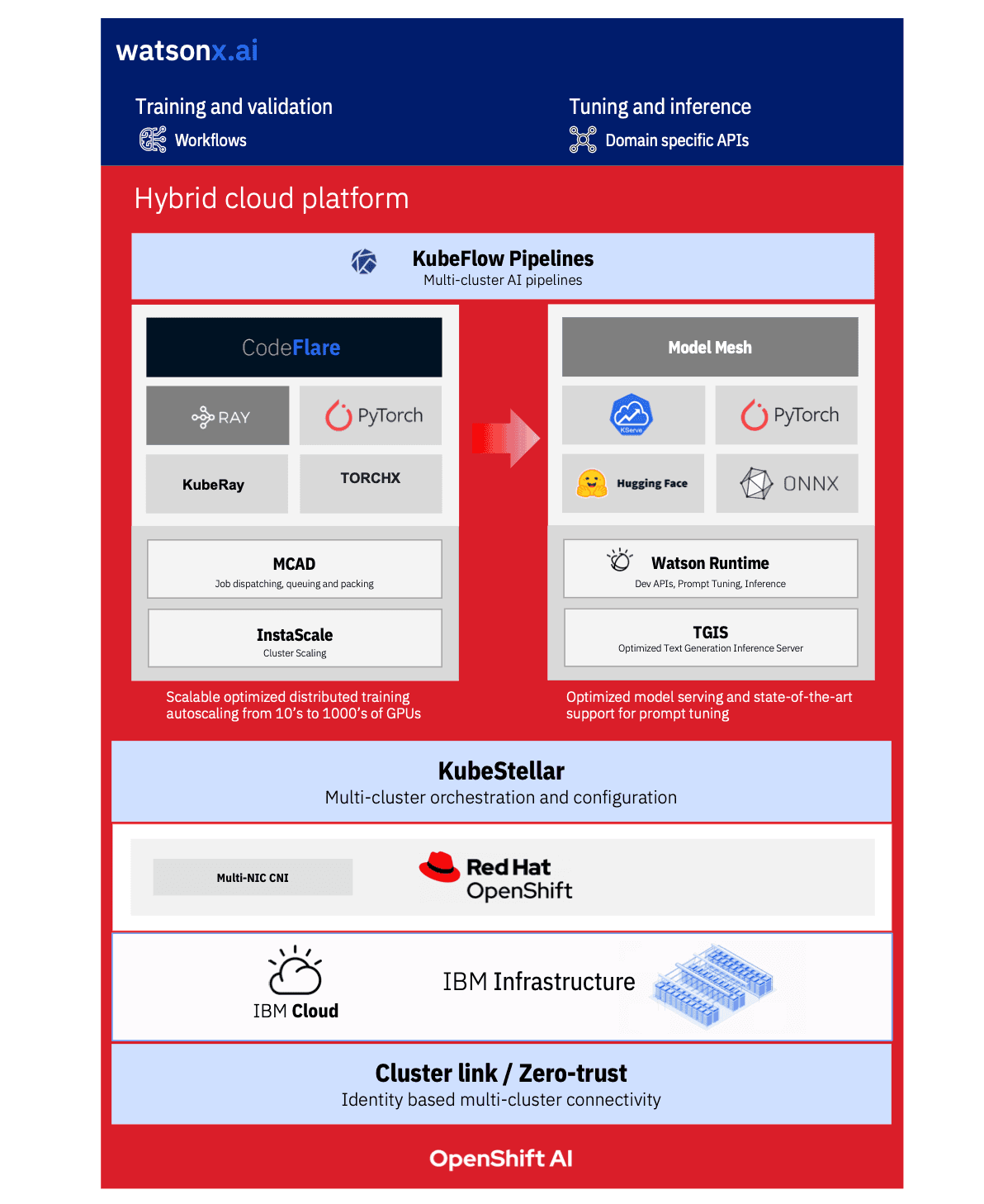
We built an enterprise-ready, cloud-native AI stack running on Red Hat OpenShift with a few goals — maximize efficient hardware utilization, provide development agility, code reuse, and simple management and scaling of infrastructure and software, and bring efficiencies in addressing each step of the AI lifecycle. Our stack serves as the foundation for watsonx, with Red Hat OpenShift AI serving as the middleware base for watsonx.ai.
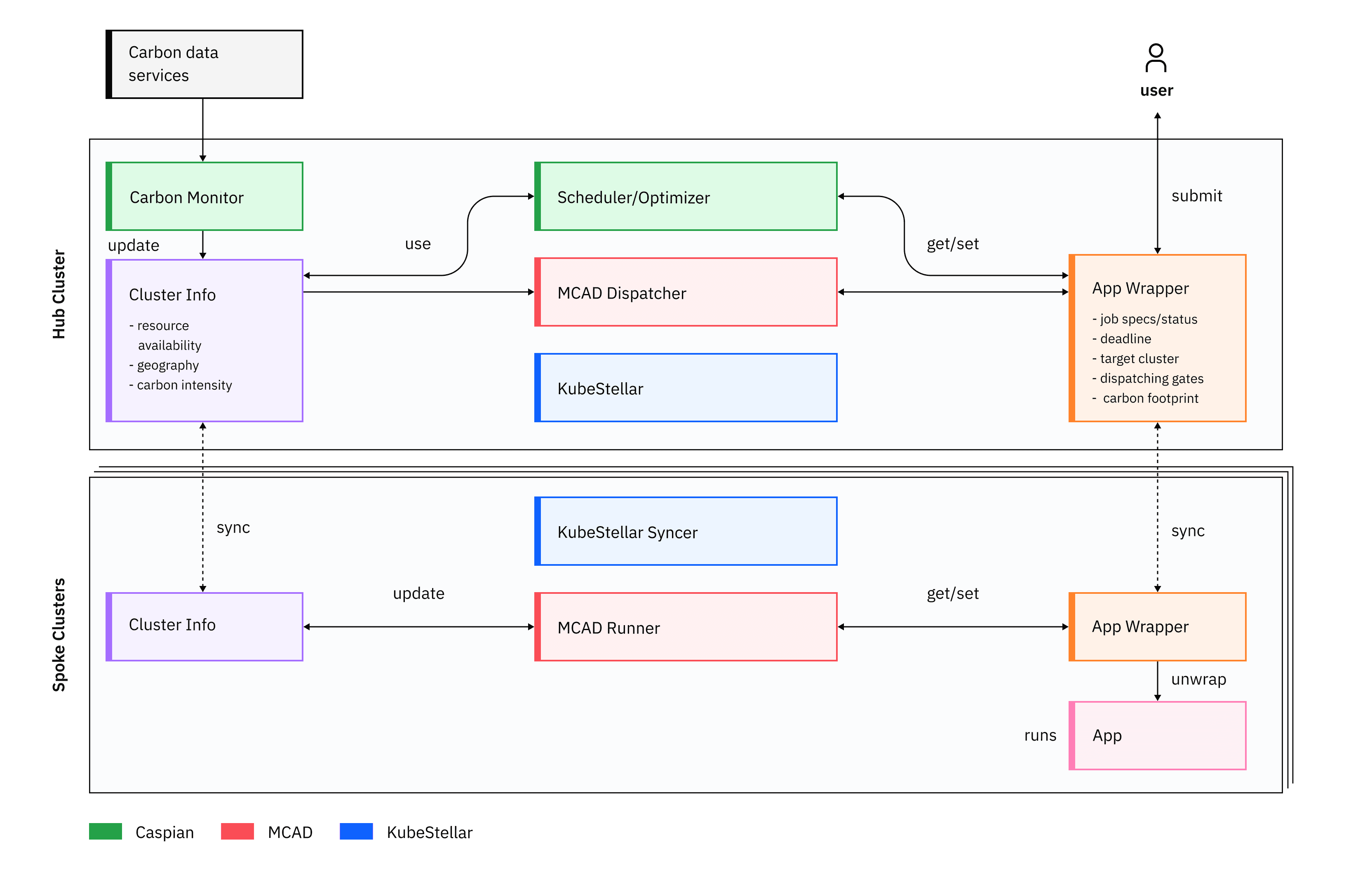
A core component of OpenShift AI is the multi-cluster app dispatcher (MCAD), an open-source project that we developed at IBM Research. It is a scheduler that helps us allocate resources and prioritize jobs to maximize the utilization of resources, and constantly monitor distributed clusters.
We're now extending and integrating MCAD with a new component, the Workflow Analyzer. The combination of MCAD and Workflow Analyzer will let us take AI workflows comprising multiple jobs, access data that may be stored in different sovereign locations, select clouds or locations, and execute each job based on available resources and runtimes while meeting regulatory data governance and compliance requirements. We then use KubeStellar to deploy the workflow jobs to the appropriate clouds and report on their execution. We’re also building a networking fabric called ClusterLink as our foundation for zero-trust networking in the multi-cloud platform.
To manage workloads in the multi-cloud, we built a scalable architecture that includes novel techniques and algorithms to optimize infrastructure cost and resilience. In edge workloads, it reduces intermediate nodes by one to three orders of magnitude, can adapt to failures with up to 11% fewer network messages than relay structures, and avoids the flash crowd problem in application configuration updates during failure recovery.
Sustainability
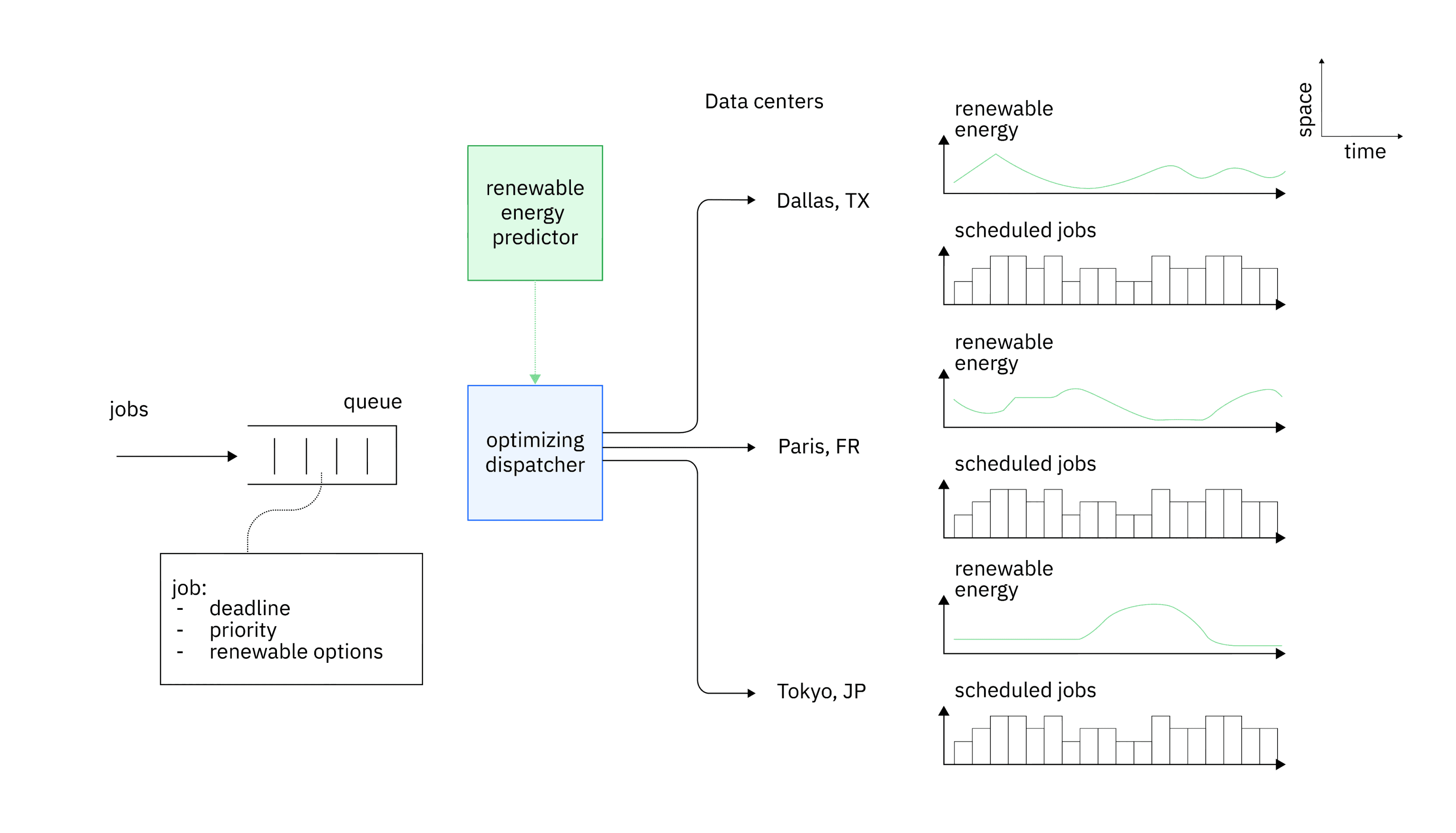
We want to make OpenShift the world’s most sustainable hybrid cloud platform. We will do that through advanced energy-aware scheduling, multi-cluster dispatching, and vertical scaling. We will combine mechanisms at multiple layers, from containers to pod scheduling and cluster-level workload queueing, while achieving multi-objective optimization. We already developed carbon-aware dispatching algorithms that consider the availability of computational resources as well as also the carbon intensity of power sources in data centers to decide the placement and scheduling of workloads. We developed an algorithm that efficiently solves the problem of workload scheduling while considering the greenness of the power sources. We exploited the capabilities of Kepler for power consumption estimation to build PEAKS, an energy-aware Kubernetes scheduler. And we built Caspian, an early prototype of multi-cluster sustainable optimized dispatching on MCAD and KubeStellar.
Enhancing Vela, IBM’s cloud-native AI supercomputer
Infrastructure for AI was a major focus for us in 2023. AI models are becoming more complex and the compute power required to train them is growing. This is why we built Vela, an AI supercomputer in the IBM Cloud. This year, wemade several enhancements to Vela that nearly doubled its capacity and dramatically improved the speed of its network. These updates allowed us to efficiently train our highly performant 20-billion parameter model and 13-billion parameter multilingual language model (the Granite series).
We deployed RoCE (RDMA over Converged Ethernet) and GDR (GPU-direct RDMA) on Vela. We gave Vela the capability to efficiently scale individual training workloads to thousands of GPUs per job. We now have much faster communication between processors, 2x-4x better network throughput, and 6x-10x lower network latency. We worked with our partners to develop a highly optimized power capping solution that allowed Vela to essentially “overcommit” the amount of power available to a rack safely. As a result, Vela is now comprised of around twice as many GPUs as it had prior to the upgrade. We also worked with the Cloud team to enhance automation in IBM Cloud, cutting in half the time it takes to find and understand hardware failures and degradations on Vela. In fact, the lessons learned from managing an environment this complex have been rolled out more broadly to improve operations across the rest of IBM Cloud’s VPC environment.
Artificial Intelligence Unit (AIU) Cluster
We first announced the Artificial Intelligence Unit, our inference accelerator, in 2022. In 2023, we deployed it in an inference cluster at our Research facility in Yorktown Heights, New York. The cluster consists of x86 nodes populated with AIU cards.

Now some of our internal data cleaning workloads — such as hate, abuse, and profanity filtering — run on the AIU cluster with comparable throughput but much lower power than on a GPU cluster. We also developed a roadmap for the AIU that will take advantage of our semiconductor technology innovations as they mature.
IBM Z
We talked about Vela and the AIU cluster but no conversation about hybrid cloud infrastructure would be complete without the world’s premier system for transaction processing, IBM Z. We saw advances in its operation in the hybrid cloud as well as the system itself. For example, when working on hybrid cloud or multi-cloud environments, clients need the assurance that their data and code in use are protected. In the case of digital assets and today’s wallet options, clients are forced to choose either speed or security. Take for example private keys. We use them in signing transactions. They’re either stored in a hot wallet that is connected to the internet or in a cold wallet that’s physically isolated or air-gapped and completely offline. One or the other, but there’s no solution to facilitate transaction signings between the two. This is a gap in protection that we’re addressing and for that, we developed an offline cold storage capability, the IBM Z Offline Signing Orchestrator. In collaboration with Consulting, we also provided a digital currency solution for governments and banks using LinuxONE, leveraging IBM Z’s crypto hardware for digital currency security.
To accelerate the modernization of applications in mainframe, we helped create the IBM Z Cloud and Modernization stack, providing confidential computing, native Z systems dev/test support in the Cloud (Wazi), and cloud native technologies like IBM Z micro services and containers. This work enables clients on multiple clouds to use Z developer tools and services.
We also helped to infuse AI in all aspects of IBM Z systems. We provided semantic query capabilities in relational databases using self-supervised neural network models shipped in SQL Data Insights. Insurance firm La Mobilière’s used it to process insurance offer recommendations faster and 94% more accurately. We created a synthetic financial transaction dataset generator and provided financial fraud detection models for anti-money laundering and credit card fraud detection. We developed a graph-based processor that transforms financial transactions into graphs and then mines fraudulent patterns in real-time.
We enabled and accelerated watsonx, deep learning, and large language models using the Deep Learning Compiler (DLC) and Z AI hardware accelerator. We integrated real-time AI into Z workloads using Watson Machine Learning for z/OS and the IBM Z AI Toolkit, and helped infuse AI in the Z operating system, providing forecasting capabilities for operating system and customer event applications.
For IBM Z systems security and compliance, we provided Validated Boot to make z/OS be OSPP (Common Criteria Operating System Protection Profile) certified, as needed by clients in the finance and public sector markets. We enabled Z applications to remotely attestate their secure execution environments and access the Z crypto hardware. We provided analytics for real time detection of data corruption and breaches. This enables recoverability from a cyber disaster by quickly determining what data and applications might be compromised. Finally, for new workloads, we provided quantum safe and digital currency encryption with a hardware design that provides 65 times faster quantum safe encryption on Z.
Storage technology
Another critical part, particularly as the size of generative AI data sets and models increases, are storage solutions for the numerous versions of training and output data, intermediate data, checkpoints, and models created during the development phase. Last August, IBM released the Jaguar 7 - TS1170 tape drive with a 50TB native cartridge capacity on the newly developed strontium ferrite-based media. This is a 2.5x leap in capacity that was enabled by technologies developed by the Research team, like the new media developed in a decade-long collaboration with Fujifilm, servo control technologies to enable 20-25 nm positioning-error signal, an optimized writer head, and reduced friction heads.

Then in October, IBM released the next-generation Flash Core Module, FCM4. It’s the only enterprise flash drive built entirely of QLC flash. To make FCM4 possible, Research provided read calibration enhancements, characterization of new charge-trap QLC flash, write heat tracking and separation, a novel pool sizing algorithm, and retention-aware health binning. The result of these contributions is a 4x increase in endurance. We also led the development of storage acceleration technologythat abstracts different data sources and presents a single accelerated global namespace to a lakehouse. We have seen an acceleration of 10x so far, and we continue to advance this technology by adding smart application-specific caching mechanisms and data locality awareness.
Advances in cryptography and AI will secure multi-cloud, decentralized environments.
Securing generative AI
As generative AI continues to reshape day-to-day communication, we're working on new tools to make generative AI more transparent. We’re calling it AI forensics. For example, while the community develops tools to detect whether content was generated by AI versus a human, evasion techniques constantly improve too. One can disguise AI-generated text by rewording it, often using another LLM. We're exploiting this vulnerability with RADAR. RADAR identifies text that’s been paraphrased to fool AI-text detectors. You can try it, it’s outperforming leading AI-text detectors.
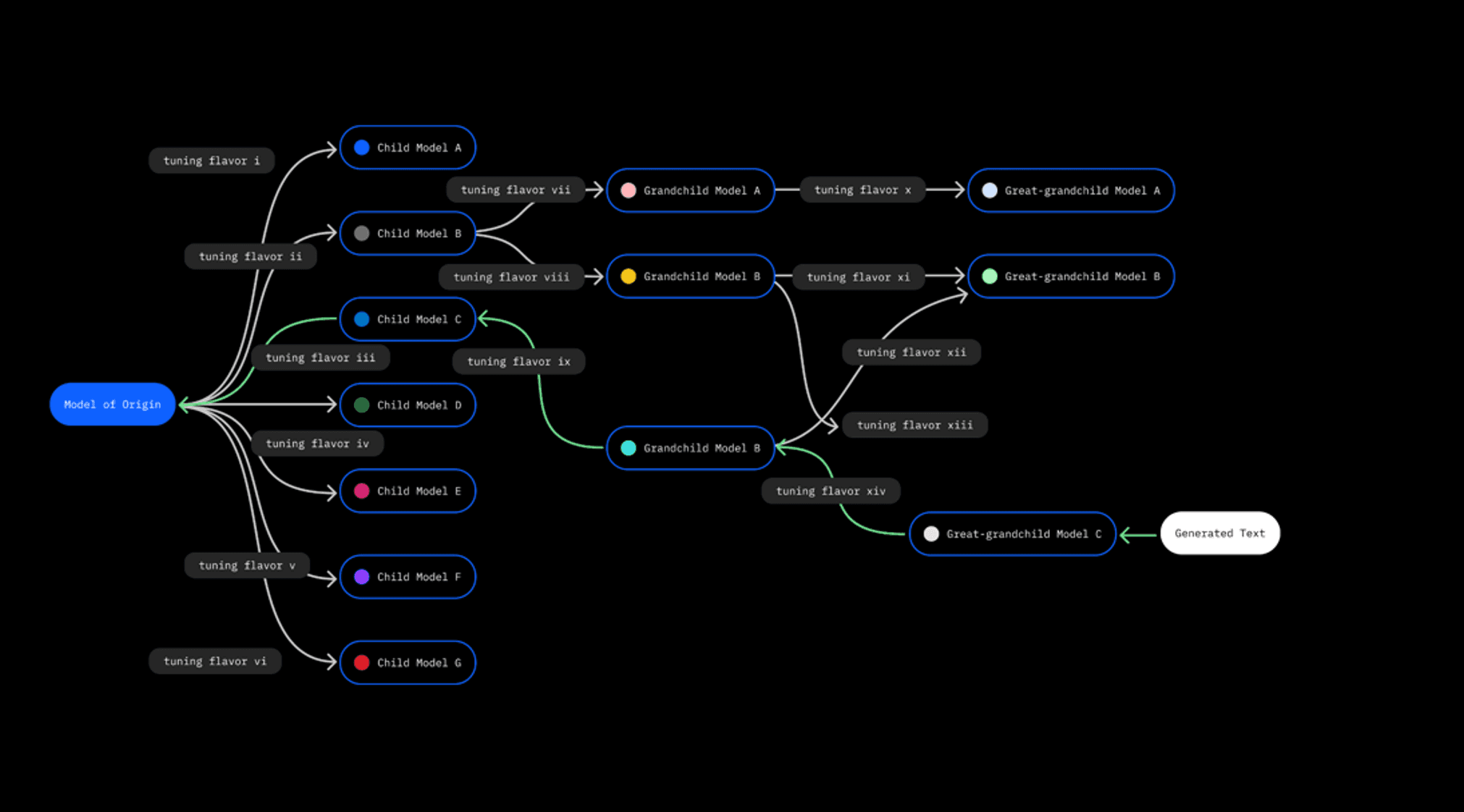
Now, once a piece of text has been confirmed as AI-generated, we need to find the model that produced it, which is harder than it sounds. You can use natural language and AI-created prompts to prod the tuned models into giving up clues pointing to the correct parent model. Our researchers built a “matching pairs” classifier to compare responses from the tuned models to select base models, and devised a method to select prompts that would elicit clues about the models’ underlying training data.
Security and compliance automation for AI workloads
Everybody wants transparent, safe, and secure generative AI. In fact, in response to the recent developments in AI, NIST released its AI Risk Management Framework on January 2023. In September, the EU released its Artificial Intelligence Act, establishing obligations for AI. In October, President Biden issued an Executive Order setting principles and priorities to govern the development and use of AI. New regulations continue to be introduced and amended.
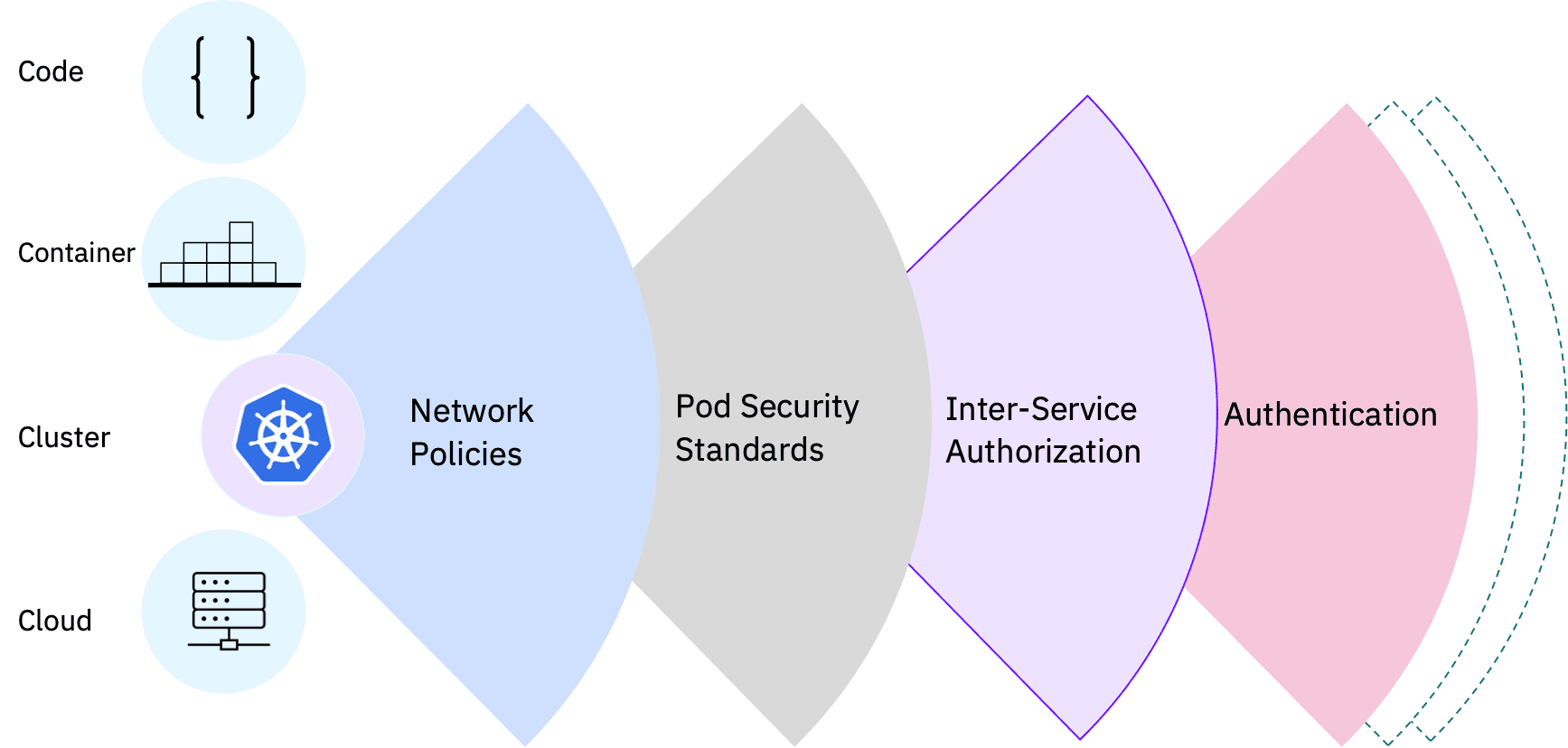
To help organizations be continuously compliant with evolving regulations, we developed an AI-driven automated policy reasoning and compliance framework that transforms unstructured and complex regulatory text into a structured representation that can be queried to assist with understanding and analyzing regulations. The queries can also allow an analyst to evaluate compliance of privacy policies with multiple regulations. Meanwhile, our research on automated guardrails — with confidential computing to encrypt AI model execution — aims to automatically protect against risks and theft of sensitive and proprietary models as enterprises leverage generative AI within their business processes.
Threat hunting
We also made major improvements to Kestrel, IBM’s open source threat hunting solution. Kestrel provides a domain-specific language tailored for threat hunting and agnostic to the underlying security products deployed. Because of our improvements, Kestrel is now up to 10x faster at data retrieval and has better support for key data sources and formats, such as Elastic ECS. We introduced Kestrel-as-a-service, a containerized service ready with JupyterHub and Kubernetes. Furthermore, we worked closely with standards bodies, such as OASIS, to expand their OpenC2 standard for cyber defense to include a threat hunting actuator profile based on Kestrel and our work in the DARPA CHASE program.
Generative adversarial networks (GAN) in malware
Complementing threat hunting to identify ongoing threats is malware detection. Over the last decade, the world has been seeing the number of security breaches constantly increasing. There has been a lot of interest in machine learning based malware detection algorithms, but these algorithms can be susceptible to adversarial malware examples and if they can be bypassed by adversarial techniques, they become useless. Methods to generate adversarial malware examples either rely on unavailable detailed information or might require unfeasible querying of a black-box system, which make them unsuitable for real-life scenarios. We developed a novel query-free, GAN-based framework to craft adversarial malware examples to evade machine learning based malware detectors. This approach leads to a decrease in the average number of detections by the anti-malware engines in VirusTotal. Work like this shows that while GANs can be a challenge to cybersecurity, they can also be a powerful tool to evaluate the performance of AI models and improve malware detection systems.
Quantum-safe cryptography
Security never stops evolving and now, with quantum computing accelerating its progress, quantum-safe cryptography increases in priority for enterprises and governments. IBM is not a newcomer in the field of quantum-safe cryptography. We are leaders in quantum computing, we are committed to building revolutionary technology. We are also committed to mitigating the risks that that technology may pose. As such, we have a long history of leadership in quantum safe cryptography. We already discussed advances in 2023 in our quantum-safe technology product when talking about IBM Quantum Safe in the quantum computing section above.
In 2022, three of the four new cryptographic algorithms that NIST selected were built by IBM Research. In 2023, NIST started a new standardization process to diversify the toolkit of quantum-safe cryptographic algorithms. We submitted three new digital signature algorithms, all accepted by NIST for competition. Our new quantum-safe algorithms will provide even broader security for our classical infrastructure in advance of future cryptographically relevant quantum computers.
Confidential computing
As we continue to manage the risk of threats, we must protect compute and reduce the attack surface exposed to attackers across the hybrid cloud. This is why we re-architected the control plane of our confidential containers to limit the capabilities of the host-side controller to the allocation and recycling of compute resources, while authorizing designated owners to manage their container workloads through a secure alternative channel. This approach guarantees seamless integration with cloud-native orchestration layers and aligns confidential containers with confidential computing. We’re preventing untrusted hosts from accessing private data and interfering with the execution of workloads within protected domains.
Besides confidential containers, enforcing control flow integrity (CFI) in the kernel (kCFI) can prevent control-flow hi-jack attacks and further enhance the security of running workloads in the multi-cloud. These attacks can be devastating as they allow an attacker to escalate privileges, take control of the host machine, or leak confidential data. We developed a new mechanism to enforce CFI using eBPF-based kCFI to implement more precise policies that can use runtime context while maintaining low performance overhead, and with the ability to enable or disable the kCFI dynamically.
Decentralized trust
Besides securing AI, advancing threat hunting and detection, addressing emerging security concerns with quantum safe cryptography, and protecting data and workloads across the hybrid cloud, we are also addressing the security challenges associated with recent trends in decentralization. One such trend is the tokenization of financial assets that is gaining traction within central and commercial banks. In last year’s letter, we talked about our framework for central bank digital currency (CBDC) and its enterprise privacy features. We also highlighted our work with HSBC and the Bank of France using the framework to develop the Bank of France’s cash distributed ledger technology platform. In 2023, that platform was chosen as one of the three solutions to be tested in the Eurosystem exploratory work on settlement in central bank money taking place in 2024.
We evolved the framework in 2023 by introducing a system identity management on a self-sovereign identity paradigm and standards. This includes cryptography optimization and interoperability of the system with civilian identity in multiple countries and future know your customer mechanisms. We designed and built a proof of concept of the full retail transaction processing system. It has a throughput of over 120k TPS, less than two seconds latency, and control on the edge. We’re also developing a strategy for quantum-ready CBDC systems, served by Project Tourbillon. Finally, we introduced cryptographic primitives to support scalable and privacy-enabled proof of liabilities, and privacy-enabled cross-validation of claims across mutually distrusting parties.
At IBM Research, we have a long history of cutting-edge computing innovation. We also have a track-record of combining our knowledge of AI with a deep understanding of science. As you learned about in last year’s letter, accelerated discovery builds on that heritage by leveraging classical computing — particularly AI, cloud, and quantum computing to accelerate the discovery of solutions that aim to make a substantial impact on the world. In 2023, we explored applying accelerated discovery to drug discovery, materials science, and climate change mitigation and adaptation. We also have our earliest examples of how quantum computing could provide a unique advantage in addressing problems in high-energy physics and cell-centric therapeutics.
Accelerating drug discovery
Researchers are moving into a new era of AI-enabled drug discovery that will accelerate the development of life-changing medicines. Last year, we shared our work integrating AI for knowledge ingestion with physics-based simulations and deep learning surrogates, automated hypothesis generation, and cloud-based experimentation. We told you about our framework for molecular generative model, where we leverage generative AI to represent the structure of molecules and predict new molecular designs. In 2023, we kept pushing the boundaries of what we can do with such integration of computing technologies and applied it to the problem of assessing whether islet autoantibody screening is effective for predicting type 1 diabetes in adolescents. We believe that scaling access to these technologies will provide a step change in drug discovery timelines.
Accelerating materials science
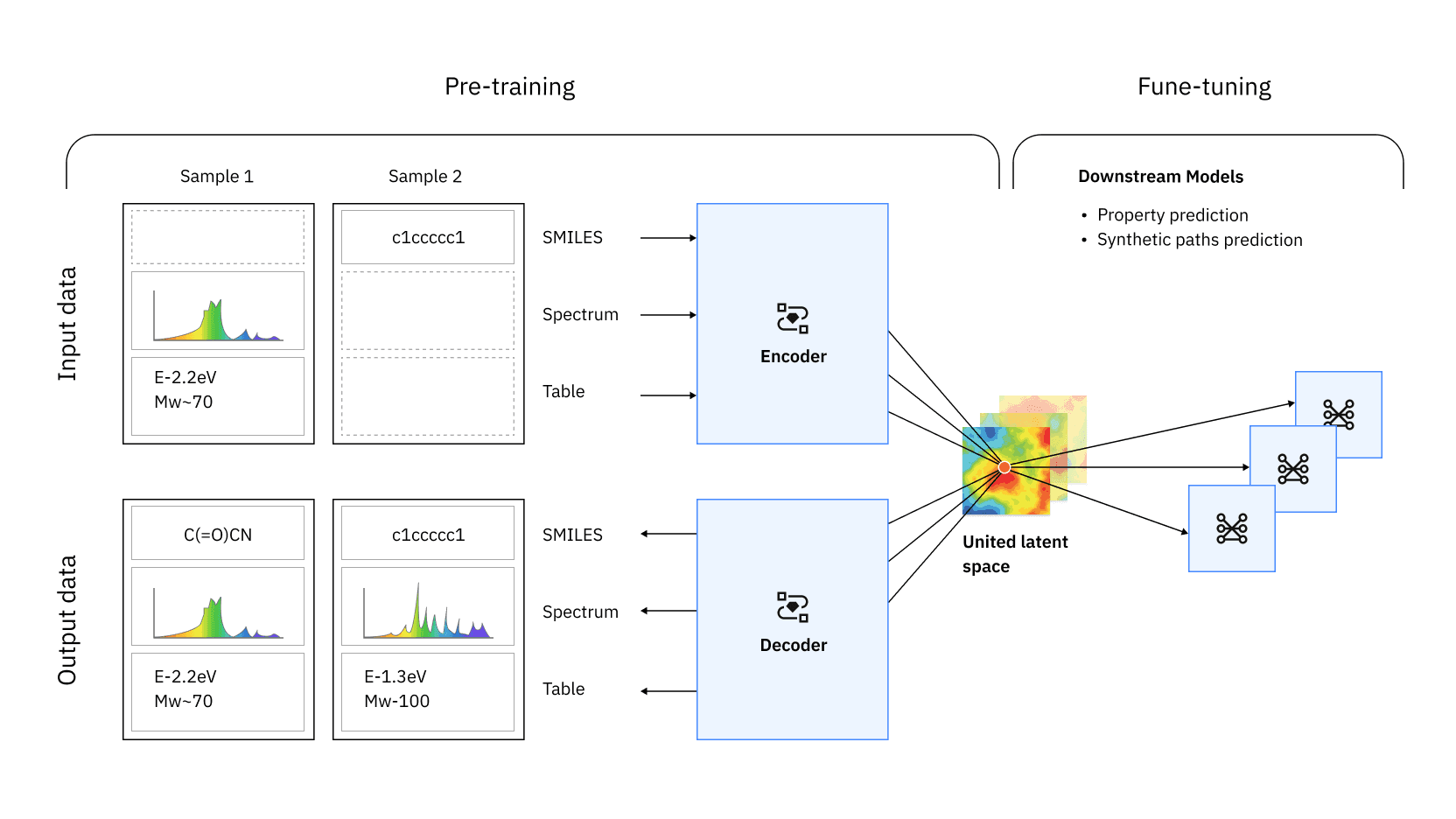
Drug discovery is only the beginning. In 2023, we presented a foundation model for material science that incorporates multiple representations of a material and data modalities on a united latent space. We also built a model that unifies molecular and textual representations through multi-task language modeling and proposed the Regression Transformer, a method that abstracts regression as a conditional sequence modeling problem to make generative AI more controllable.
AI for carbon capture
A separate but related example is carbon capture chemistry. Carbon capture, storage, and utilization is considered one of the key strategies required to reduce carbon dioxide emissions and their impacts on climate change. However, despite decades of intensive research, making carbon capture economically viable remains an enormous challenge. Most high-throughput computational screening studies for carbon capture and related problems use grand canonical Monte Carlo simulations that depend on the choice of force field parameters and partial charges. Therefore, we need databases to do a comprehensive impact evaluation. In 2023, we presented a database of simulations of CO2 and N2 adsorption isotherms on 690 metal-organic frameworks taken from the CoRE MOF 2014 database. The result is CRAFTED, (Charge dependent, Reproducible, Accessible, Forcefield-dependent, and Temperature-dependent Exploratory Database of adsorption isotherms). CRAFTED provides a convenient platform to explore the sensitivity of simulation outcomes to molecular modeling choices at the material (structure-property relationship) and process levels (structure-property-performance relationship).
While most of our work is focused on turning innovations into products for IBM and our clients, we never stop performing theoretical and longer-term scientific research. Below are some of the major efforts we carried out in 2023, some of which have already matured into work that will make its way into product roadmaps soon.
Neuro-inspired computational models
Algorithms inspired by neural dynamics, human attention mechanisms, and synaptic eligibility traces have the potential to dramatically increase the energy efficiency of AI computations. Hence, we’re investigating neuro-inspired circuit motifs for non-transformer architectures with richer feature extraction capabilities. In hyper dimensional computing (aka vector symbolic architectures), we have a neuro-inspired computational model that encodes symbolic data on a high-dimensional space of randomly drawn vectors of the same, fixed dimensionality, with the information equally distributed over all the components of the vector similar to how information is represented in the brain as distributed over many neurons.
These neuro-vector symbolic architectures (NVSA) combined with analog AI could allow us to solve orders of magnitude larger problems than would be possible otherwise, decreasing the computational time and space complexity while increasing the energy efficiency of the computation. For example, we showed that our NVSA can decompose joint representations to obtain distinct objects (i.e., solve the binding problem), which neural networks cannot. One such problem is disentangling the attributes of a sensory signal for sensory perception and cognition. We demonstrated that NVSA can extend in-memory computing to artificial general intelligence workloads and will continue to explore how to expand AI capabilities on IBM’s emerging AI hardware.
Understanding natural phenomena
We developed a framework that combines logical reasoning with symbolic regression to derive models of natural phenomena from experimental data and axiomatic knowledge. We call it AI-Descartes and it follows our belief that information theory, logic, and mathematical optimization can be leveraged to provide formal interactions between logical, deductive knowledge and mathematical models in a computationally effective way to assist in the scientific discovery process. Using this work, we aim to create a workbench to support practitioners in developing, integrating, and validating hypotheses in a statistically rigorous and replicable way.
We also demonstrated the first reversible chemical reactions controlled by nanoprobe voltage pulses and are learning about chemical reaction dynamics and excited states at a bond-level resolution. We believe this work can lead to molecular machines, new materials created bond-by-bond, and potentially game-changing materials properties for future computing devices.
Atomic force microscopy for molecular mixture characterization
IBM has a long history in microscopy. IBM scientists invented the scanning tunneling microscope in 1981 and the atomic force microscope in 1985. It’s a history that we continue and now, we developed ultra-high-resolution atomic force microscopy to study complex molecular mixtures. Contrary to all other methods for structure elucidation, which rely on ensemble measurements, ours relies on assigning structures of single molecules.
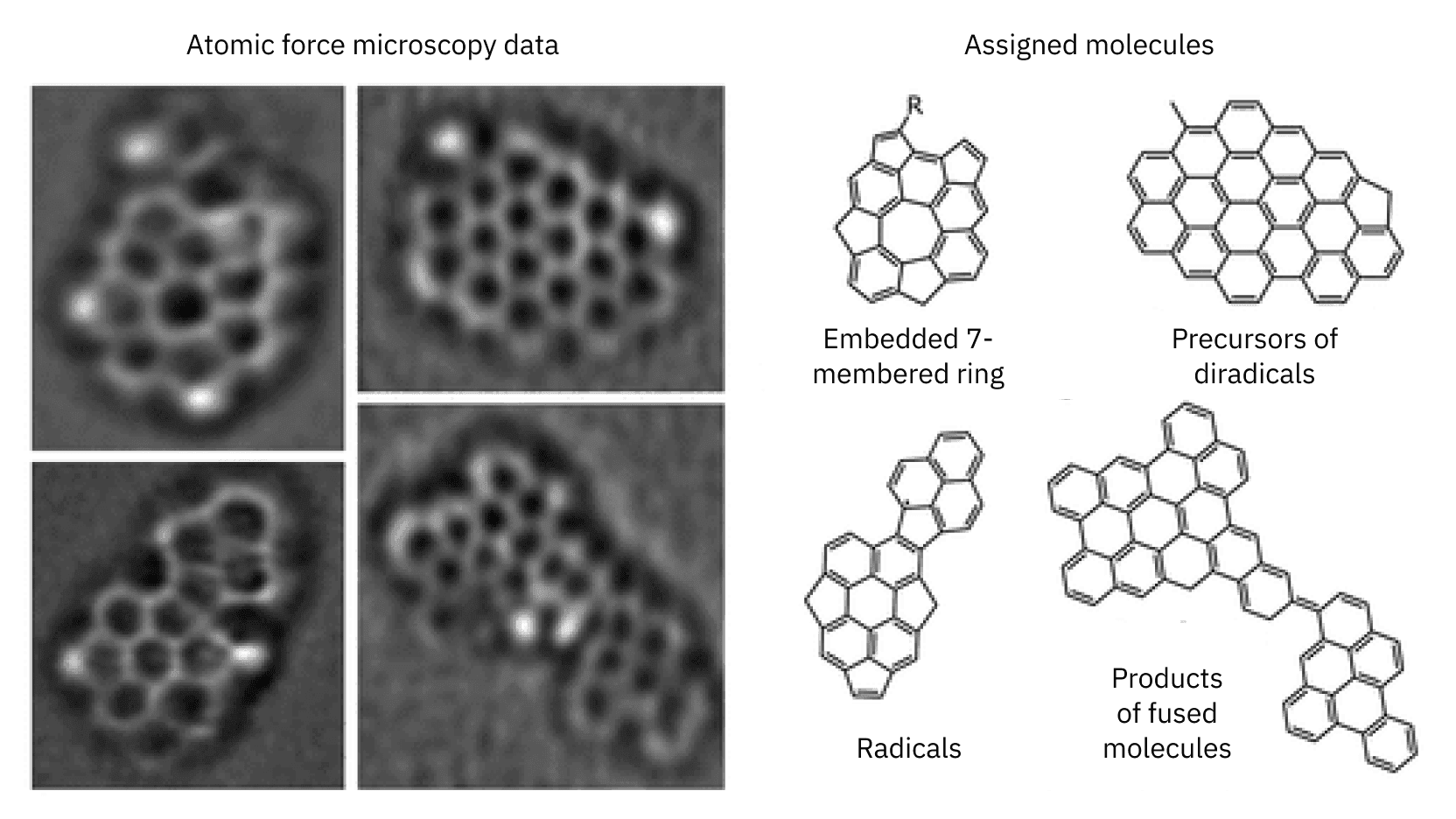
We obtained the first atomically-resolved images of molecules from it. By assigning individual molecules in molecular mixtures, we uncovered reaction pathways for particle growth in incipient soot, one of the most important objectives in the research field of combustion, with implications for cleaner combustion, climate, and health. And in collaboration with NASA, we obtained the first atomically resolved molecules of extraterrestrial origin.
At IBM Research, we are delivering on our mission to be the organic growth engine for the company and to create what's next in computing. We are continuously building innovations for IBM, our partners, and the world. And this year, the pipeline from innovations to products moved faster than ever before. It was a massive year for AI and for IBM’s place in the AI landscape. We developed the platform and many of the models that make up watsonx in record time. We worked with partners across industry and academia to launch the AI Alliance, a group committed to building an AI future that is open and equitable. We developed new AI chip platforms that will help efficiently power the AI workloads of tomorrow.
In quantum computing, we made possible the first investigations of the utility of quantum computing, introduced Quantum System Two — the building block of quantum-centric supercomputing, redesigned our processors and gates with Heron, unveiled the first major evolution of the world’s favorite quantum SDK — Qiskit, and published a roadmap that will take us from utility to large error-corrected machines.
Our advances in semiconductors, AI, quantum computing, and hybrid cloud outlined in this letter signify the impact that IBM Research has made on many of the technologies that define how the world works today. But when we start to put all these pieces together, we see a future for computing where intractable problems and pressing issues can be solved. This is perhaps clearest at our redesigned Think Lab in Yorktown Heights, New York, which houses our new Quantum System Two and AIU cluster. These machines are already working on solving real-world problems. We’re one step closer to making our vision of computing — the convergence of bits, neurons, and qubits — a reality. We’ll continue down this path in the year ahead, looking to increase the performance and energy efficiency of computation, while making the process as seamless as possible for the end user.
To us, this is the future, built right. We’re looking forward to the journey ahead.