In-memory physical superposition meets few-shot continual learning
Deep convolutional neural networks (CNNs) have achieved remarkable success in computer vision tasks, like image classification. This is the result of the availability of a large amount of training samples, as well as being able to leverage huge computational and memory resources.
This, however, poses challenges for their applicability to standalone smart agents deployed in new and dynamic environments. In these cases, there is a need for agents to continually learn about novel classes they encounter from very few training samples without forgetting previous knowledge of old classes. At the same time, these agents need to learn efficiently even when computing resources are extremely limited. Our research aims to find solutions to these problems via the physics of in-memory computing, and mathematical models that can efficiently run on in-memory computing hardware.
To meet the aforementioned constraints, we approach the continual learning problem from a counterintuitive perspective in which the curse of high dimensionality is turned to a blessing. The key insight is to exploit one of the intriguing properties of the issue: Independent random high-dimensional vectors will be dissimilar and so can naturally represent different classes, which has been already exploited in few-shot learning (as we’ve discussed in our previous work). By doing so, the representation of a novel class is not only incremental to the old learning, but also avoids potential interferences.
This insight allows us to design a flexible architecture with an inevitably growing portion of memory storage, in which new examples and new classes can be incrementally stored and efficiently retrieved (or recalled)1. This has been done by exploiting the analog storage capability of the non-volatile memory devices. Specifically, we exploit the in-situ accumulation via progressive crystallization of phase-change memory (PCM) devices to realize physical superposition of multiple training examples on the same set of PCM devices.
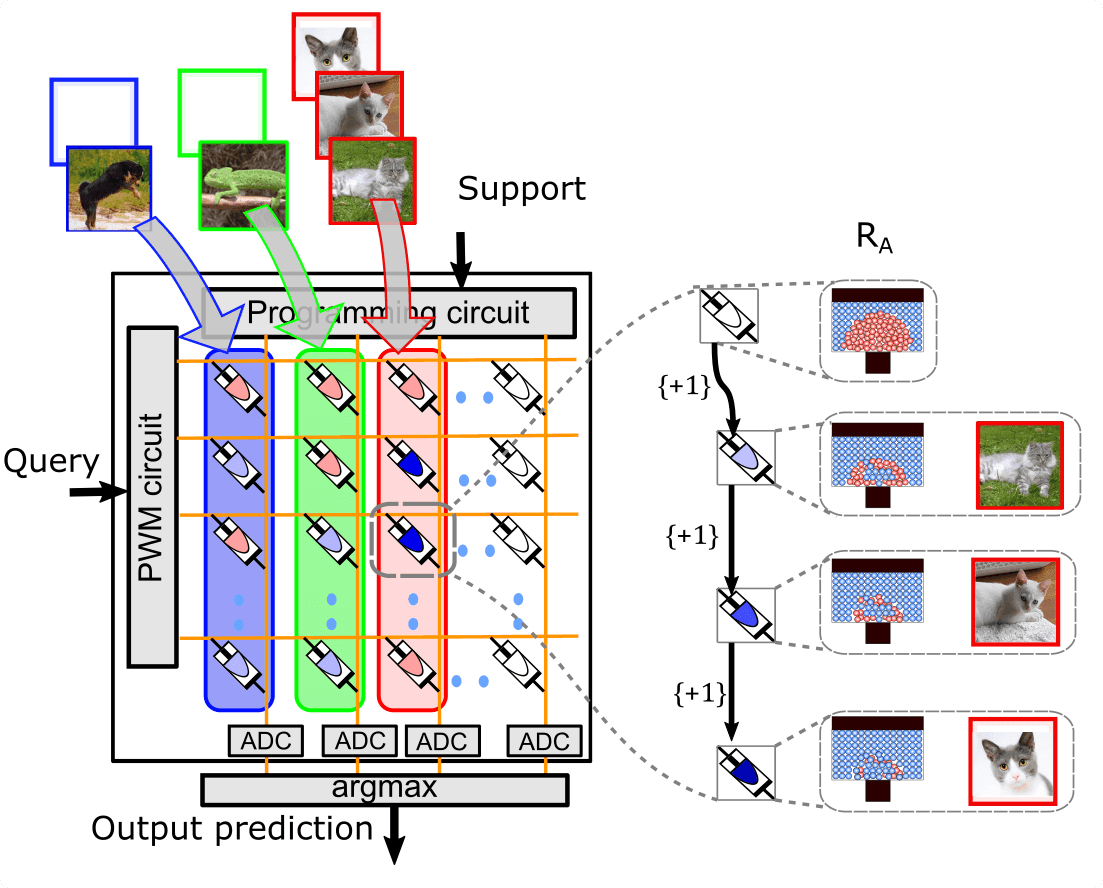
We’ve shown the first demonstration of a few-shot continual learning algorithm on the in-memory computing hardware. Our most prominent result enables deep CNNs to learn continually at scale under extreme constraints, such as very few training samples and no retraining cost for CNNs. Experiments on datasets of natural images (like CIFAR100, and miniImageNet) show that the classification accuracy of our in-memory hardware is within 1.28% to 2.5% of a baseline software using costly, full-precision arithmetic and noiseless memory. More importantly, our approach achieves the lowest energy during both learning and inference.
Continual learning faces several issues, including catastrophic forgetting, class imbalance problem, and interference from the past classes. We avoid these issues systematically in this work, where high-dimensional quasi-orthogonal vectors are assigned to every class with the aim of reducing interference. This can’t be achieved with other methods, as they fail to support a larger number of classes than the vector dimensionality of the layer they are connected to. Our class vectors are progressively stored in the PCM devices where they can be selectively updated using physical superposition.
Unlike animals, who can adapt throughout their life, many machine-learning algorithms, including deep neural networks, are fixed during their lifetime, and such limiting their use cases. The model is trained once with parameters frozen during inference. Our approach allows models to continuously learn and evolve based on the input of increasing amounts of data while retaining previously learned knowledge without overtaxing compute-memory resources.
The research has been carried at IBM Research - Zurich and IBM’s AI Hardware Center in Albany, New York, in collaboration with ETH Zurich.
Date
References
-
G. Karunaratne, M. Hersche, J. Langenegger, G. Cherubini, M. Le Gallo-Bourdeau, U. Egger, K. Brew, S. Choi, I. OK, M. C. Silvestre, N. Li, N. Saulnier, V. Chan, I. Ahsan, V. Narayanan, L. Benini, A. Sebastian, A. Rahimi, “In-memory realization of in-situ few-shot continual learning with a dynamically evolving explicit memory,” IEEE European Solid-state Devices and Circuits Conference (ESSDERC), 2022. ↩