IBM Research - Israel
Artificial Intelligence
We are innovating and developing core technologies that improve the state-of-the-art in such areas as natural language processing and generation, computer vision, speech technologies, optimization, and AI trust. Our teams create technologies to solve business problems in areas such as customer care, business analytics, process automation, and asset management. The data we handle includes: unstructured data, such as text, images, and speech; semi-structured data; and traditional structured data.
News and Blogs

What is retrieval-augmented generation?
Retrieval-augmented generation (RAG) involves grounding large language models in external data for better results. ISRL researchers are working on this solution, described in this IBM Research blog post.
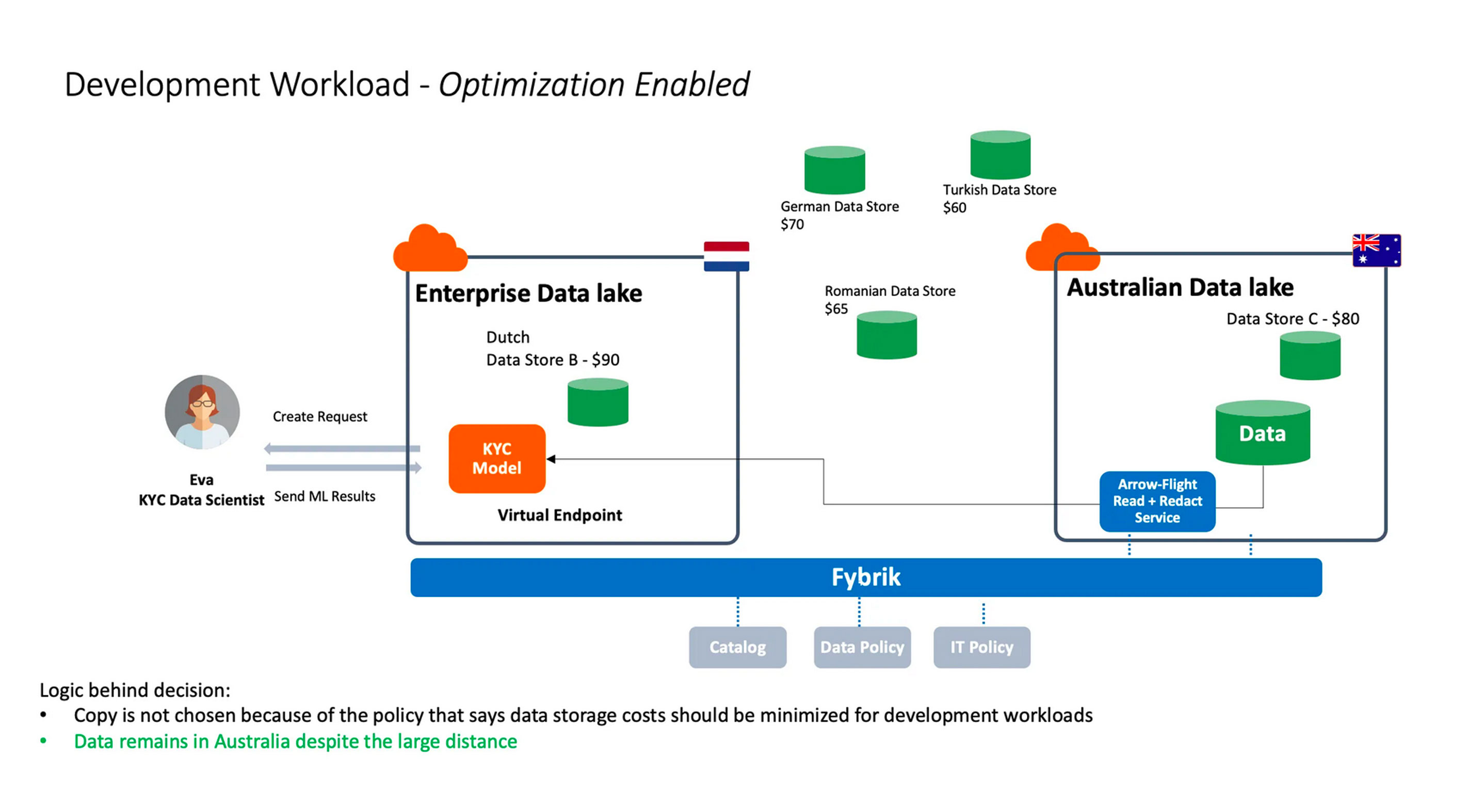
IBM and ING Optimize Data Usage Across Clusters
ING and IBM Research have partnered to add automatic IT optimization into Fybrik. In this post, ISRL researchers explain how Fybrik now addresses both governance requirements and IT infrastructure preferences.

Multi-agent and energy-efficient AI models are the next big thing
Project Debater is already capable of reasoning, yet even more is possible with cutting-edge language models, as researcher Noam Slonim explains in this podcast.

What is synthetic data?
According to researcher Ateret Anaby-Tavor, the push of a button can yield thousands of sentences to fill a chatbox's knowledge gaps -- you just need to evaluate and filter them. Learn more in this blog post.
Research Projects
|
Document Understanding |
Business documents are central to many corporate processes and lie at the heart of digital transformation. Such documents include contracts, loan applications, invoices, purchase orders, financial statements, and many more. The information in these documents is presented in natural language and is often unstructured. Understanding these documents is challenging, due to complex document layouts and content such as tables, charts, infographics. It is often even more challenging because of poor quality, noisy scans, or inadequately accurate OCR. The ability to read these business documents, either programmatically or by OCR, interpret their content so that it can be used in downstream automatic business processes is referred to as Document Understanding. We are treating this as a multi-disciplinary challenge, spanning across computer vision as well as natural language understanding, information representation, model optimization, thus advancing the state of the art in document understanding. In 2021, we participated in a workshop and shared publications about this research. Here is a link to all of the papers accepted at that workshop, several of which are from IBM Learn more about Deep Document Understanding on the IBM Research Blog |
|
Conversational Text to Speech |
The voice channel is a crucial element in customer-care scenarios, especially over the phone, and text-to-speech (TTS) systems play a fundamental role in establishing and maintaining a positive customer experience. |
|
Advanced Speech Classification |
Human speech is a rich signal that carries with it a vast amount of information. In addition to words, the speech signal encodes information about the speaker’s identity, language, accent, emotions, and physical state, that may be particularly useful for analyzing customer speech to improve the service and customer experience. |
|
Customer Care |
Our team is advancing the research for Watson Assistant, the AI-powered virtual agent that provides customers with fast, consistent, and accurate answers across multiple messaging platforms, applications, devices, and channels. we're helping Watson Assistant learn how to provide even better answers to common questions through the website, social media, chatbots, or with customer support agents. |
|
AI-powered Business Automation |
Automation improves business performance by making all information-centric jobs more productive; AI accelerates and further scales automation. We discover, generate, and improve business processes with AI, making automation trustworthy for employees and enterprises alike. We automate every enterprise, one at a time, with a focus on asset management, facility management and supply chain processes. Our innovations arrive to market via research lead pilots, IBM’s Automation products and IBM Sustainability Software’s product. |
Publications
|
IBM researchers in Israel publish a wide variety of work every year as part of their work on research projects in the lab, in collaboration with other researchers and scientists in IBM, and together with academic and industrial partners from around the world. Researchers in our group publish works at conferences and in scientific journals such as the AAAI conference, Nature, the ICASSP conference, NeurIPS, and others. |
Tools & Code
Label Sleuth
An open source no-code system for text annotation and building text classifiers.
Project Debater's Early Access Program
We offer free access to these services as Cloud APIs for non commercial academic use. The early access website is available at early-access-program.
Low-Resource Text Classification Framework
A framework for experimenting with text classification tasks, focusing on low-resource scenarios, and examining how active learning (AL) can be used in combination with classification models from Ein-dor et al. (2020) paper.
Intermediate Training using Clustering
Intermediate training of BERT in an unsupervised manger improves topical classification when labeled data is scarce. Code from ACL paper by Shnarch et al. (2022)
AI Privacy and Compliance Toolkit
A toolkit for tools and techniques related to the privacy and compliance of AI models. The anonymization module contains methods for anonymizing ML model training data, so that when a model is retrained on the anonymized data, the model itself will also be considered anonymous. The minimization module contains methods to help adhere to the data minimization principle in GDPR for ML models. It enables to reduce the amount of personal data needed to perform predictions with a machine learning model, while still enabling the model to make accurate predictions. This is done by by removing or generalizing some of the input features.
Academic Collaboration
|
Collaborate with our researchers on a wide range of NLP (Natural Language Processing) topics ranging from conversational agents and neural information retrieval to computational argumentation. |
Let's talk
We're always happy to talk. Feel free to get in touch.


