IBM RXN for Chemistry: Automatically cleaning chemical reaction datasets

Not everyone uses language the same way — even when it is, well, the exact same language.
After all, there are dialects, unusual grammar or sentence constructions, phonetics and other linguistic idiosyncrasies — all of which may indicate distinctive patterns only certain individuals use. When solving crimes, for example, a forensic linguist can identify criminals by using language outliers or entries that divert from the standard in written or recorded evidence.
Just like language, organic chemistry datasets also depend on grammar and syntax structures. Chemically incorrect entries in datasets are equivalent to dialects and unusual grammar. Compiling and categorizing datasets requires either the use of automatic knowledge extraction technologies or curation techniques by domain experts. In both cases, the datasets have a high error rate. That’s why our team has turned to AI — to better understand this concept of “chemistry linguistics.”
Do you swear to tell the truth, nothing but the truth?
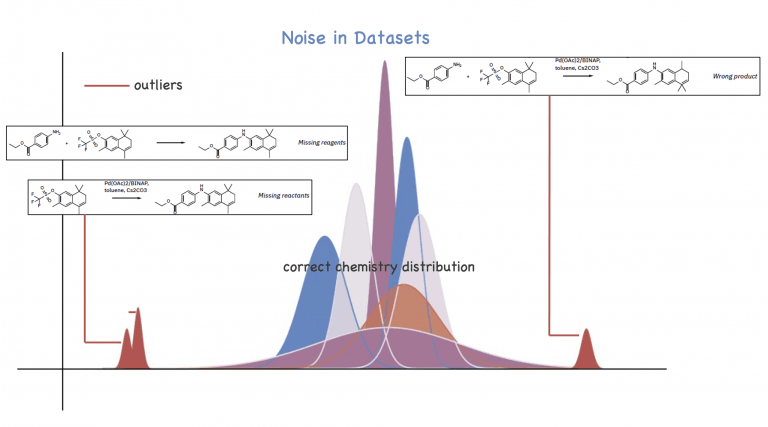
Of course, we couldn’t exactly put our AI model on the stand and ask it such a question. But in our latest paper, “Unassisted Noise Reduction of Chemical Reaction Data Sets” in Nature Machine Intelligence,1 we explore the application of NLP techniques to automate the identification of “language outliers” or “noise” in chemical datasets (Figure 1). — the divergences and nuances of linguistic expressions from a standardized language.
Earlier in 2018, we created an online platform called RXN for Chemistry using Natural Language Processing (NLP) architectures in synthetic chemistry. Specifically, we used Molecular Transformer,2 where chemical reactions are represented by a domain-specific language called SMILES, or Simplified Molecular Input Line Entry System, is a notation system for representing molecules and reactions.SMILES. Chemical transformations are framed as translation from reactants to products, similar to translating, say, English to Spanish. This platform is now available to the global chemistry community.
While our AI forward-reaction-prediction model functions at an accuracy rate of more than 90 percent, the presence of language outliers that diverge from standard linguistic rules defining the language of chemistry is the next big challenge. As this can be detrimental to the learning phase of an AI model, we put on our forensic linguistic hats on and began investigating.
In chemical datasets, the presence of chemically false statements that do not belong to the underlying true data distribution of a specific chemical case can have negative effects on the training phase of an AI model. This is comparable to learning a local language on the street or through conversation, rather than from a standard language book or teacher. The latter may naturally divert from the standard. A learner will then automatically absorb any errors or language outliers, and once exposed to the standard, will eventually begin to mix expressions and pronunciations, not necessarily aware of what is linguistically correct.
Similarly, if the models we build learn on a large amount of noisy data full of incorrect chemical grammar, pronunciation and syntax, they will struggle to understand how to properly transform one molecule into another. Essentially, large chemical datasets are used as vast ground truth collections of “chemical” sentences, which the AI model repeatedly observes and learns during “language acquisition” to be able to describe chemical transformations. This process creates the language architecture in a similar way humans acquire a language. Noisy or faulty linguistic examples, then, act as offenders or outliers in the space of chemical reactions.
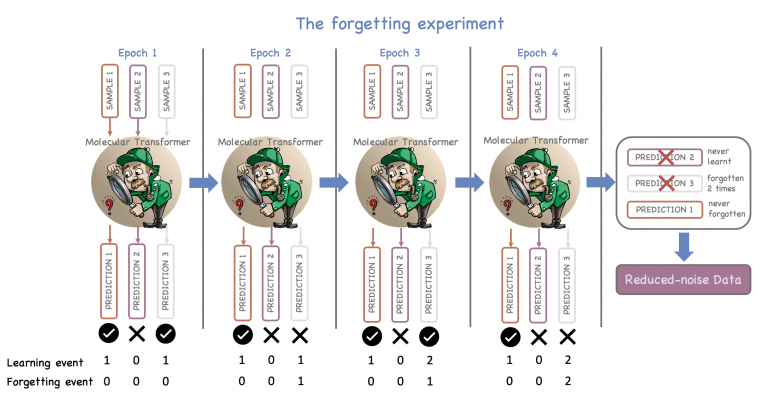
While there are other approaches to remove noise, they either rely on impractical human curation or heuristics. With respect to human curation, the percentage of errors grows exponentially over time. Applying heuristics can be good up to a certain point, but it is not easily scalable and can overlook important information. Our research identifies a well-known weakness of the AI models, known as “catastrophic forgetting,” as a way of pinpointing and removing noise.
At different steps (referred to as “epochs”), an AI model can experience a “blackout” and not be able to recall correctly what it had previously learned before. Sort of like when we humans cannot recall a word or a specific piece of information that we learned in the past. Information learned and forgotten many times can potentially be noisy and should be discarded from the training set. The process is schematically shown in Figure 2. We demonstrate in our work that scientists can turn “catastrophic forgetting” into an effective strategy that identifies and eliminates noisy outlier entries from chemical datasets. The notion is that if the expressions are outliers of the underlying true grammar distribution, the model will struggle to learn them.
Imagine you want an AI model to predict the recipe for pizza. If the model cannot distinguish between flower and flour, we could likely end up with a warm, colorful salad. To a chef, this may be the latest gourmet trend. But to the rest of us, the underlying distribution of the recipe clearly designates flower as a noisy and incorrect entry in our recipe collection. The same errors can occur in chemical reactions where the translation happens from the language of precursors to the one of products (as shown in Figure 3).

But what is typically tagged as a noisy reaction? This is where the beauty of our method comes in: we don’t need to know it in advance. The noise might be grammatical or syntactical errors in the language of chemistry (from SMILES) due to incorrect extraction of chemical records from unstructured data sources, which would not make the reactions viable from a chemical perspective. The noise could even be more subtle, such as products with the wrong stereochemistry, missing reagent information from a reaction, or incomplete reagent specification.
Taking into consideration all possible forms of noise found in a chemical reaction, we could resort back to a tedious corpus of rules that requires continuous updates, which would definitely not cover every type of noise out there. However, we would prefer to rely on our AI models which intrinsically have a statistical representation of that noise thanks to their ability to learn the underlying distribution representing the data rather than memorizing the data itself.
Again, if the samples do not belong to the main underlying distribution of the dataset, the model will struggle to learn them. The typical learning and forgetting patterns during training provide an effective way to tag the noisy, chemically incorrect entries and remove them from the original dataset so that the AI model only learns a standardized chemical language.
In life, we are always taking tests. It is no different for our AI models. So we implemented an automated way to cherry-pick noisy examples. To make sure what we were removing was actually incorrect chemistry language, we also added artificial noise to our dataset. This allowed us to check and confirm that all introduced noise was actually properly tagged and removed.
For the final evaluation, we took a test set never seen by the model trained to use the cleaned data sets, and compared performances with respect to the results of the model trained with the uncleaned dataset. Most of the metrics analyzed showed an increase in performance where the model was trained on cleaner data, particularly for retrosynthesis. In this case, the model was more capable of generalizing the unseen data.
By comparison, when we removed chemically incorrect entries using a reaction template strategy (NameRXN),3 the performance of the model drastically decreased, showing the limits of a more traditional rule-based, noise-removal strategy in controlling the loss of important distribution information during the cleaning process.
What it comes down to: our strategy opens up an array of possibilities in the world of unassisted noise-reduction of datasets for AI model training. Our noise cleaning method brings attention to the importance of the quality of datasets in the context of machine learning. Cleaning a dataset is now an automated task that takes only a few hours and can remove the noisy uncertainty that comes with large collections of chemical reaction data.
If only learning a language could be that simple…
Date
29 Mar 2021Notes
- Note 1: SMILES, or Simplified Molecular Input Line Entry System, is a notation system for representing molecules and reactions. ↩︎
References
-
Toniato, A., Schwaller, P., Cardinale, A., Geluykens, J. & Laino, T. Unassisted noise reduction of chemical reaction datasets. Nat Mach Intell (2021) ↩
-
Schwaller, P. et al. Molecular Transformer: A Model for Uncertainty-Calibrated Chemical Reaction Prediction. ACS Cent. Sci. 5, 1572–1583 (2019). ↩
-
NextMove Software. https://nextmovesoftware.com/. ↩